As always, the silliest photo is the best photo. Left to right: aerozol, zas, outsidecontext, mayhem, yvanzo, bitmap, monkey, kellnerd, akshaaatt, reosarevok, laptop: atj, lucifer
A year has flown by and once again the MetaBrainz team found itself in the MetaBrainz HQ in Barcelona, Spain, for #summit23. And once again we were munching on a mountain of international chocolates, hiking Mt Montserrat, bird-watching, groaning at terrible puns, testing out mayhem’s Bartendro cocktail robot (some of the team committing themselves too thoroughly to this testing), and of course discussing everything and anything MetaBrainz related. This year we had a longer summit, taking place over the week instead of the usual weekend, broken up into three days of presentations, followed by two days of hands-on ‘hacking’.
We’re pleased to announce that we have just released acoustic similarity in AcousticBrainz. Acoustic similarity is a technique to automatically identify which recordings sound similar to other recordings, using only the recordings themselves, and not any additional metadata. This feature is available via the AcousticBrainz API and the AcousticBrainz website, from any recording page. General documentation on acoustic similarity is available at https://acousticbrainz.readthedocs.io/similarity.html.
This feature is based on work started by Philip Tovstogan at the Music Technology Group, the research group that provides the essentia feature extractor that powers AcousticBrainz. The work was continued by Aidan Lawford-Wickham during Summer of Code 2019. Thanks Philip and Aidan for your work!
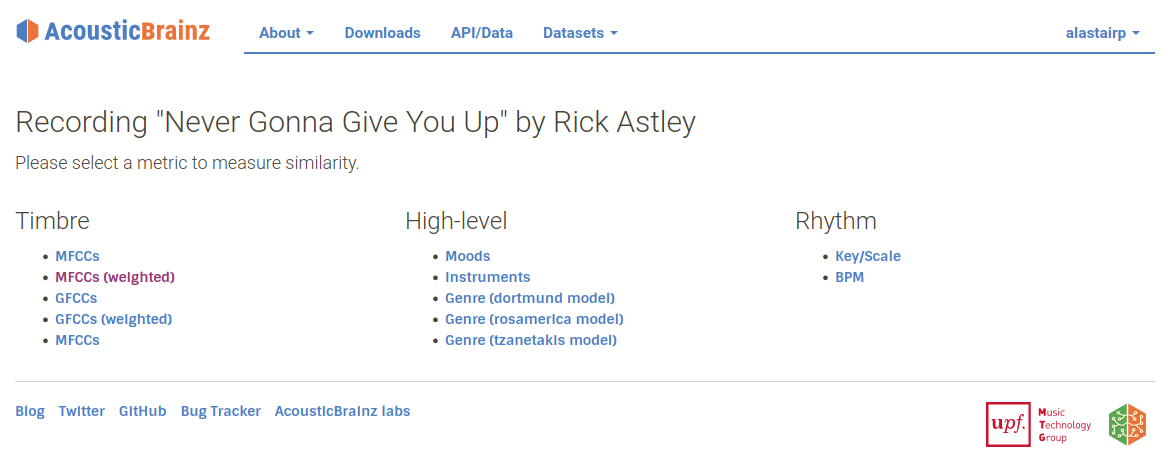
From the recording view on AcousticBrainz, you can choose to see similar recordings and choose which similarity metric you want to use. Then, a list of recordings similar to the initial recording will be shown.
These metrics are based on different musical features that the AcousticBrainz feature extractor identifies in the audio file. Some of these features are related to timbral characteristics (generally, what something sounds like), Rhythmic (related to tempo or perceived pulses), or AcousticBrainz’s high-level features (hybrid features that use our machine learning system to identify features such as genre, mood, or instrumentation).
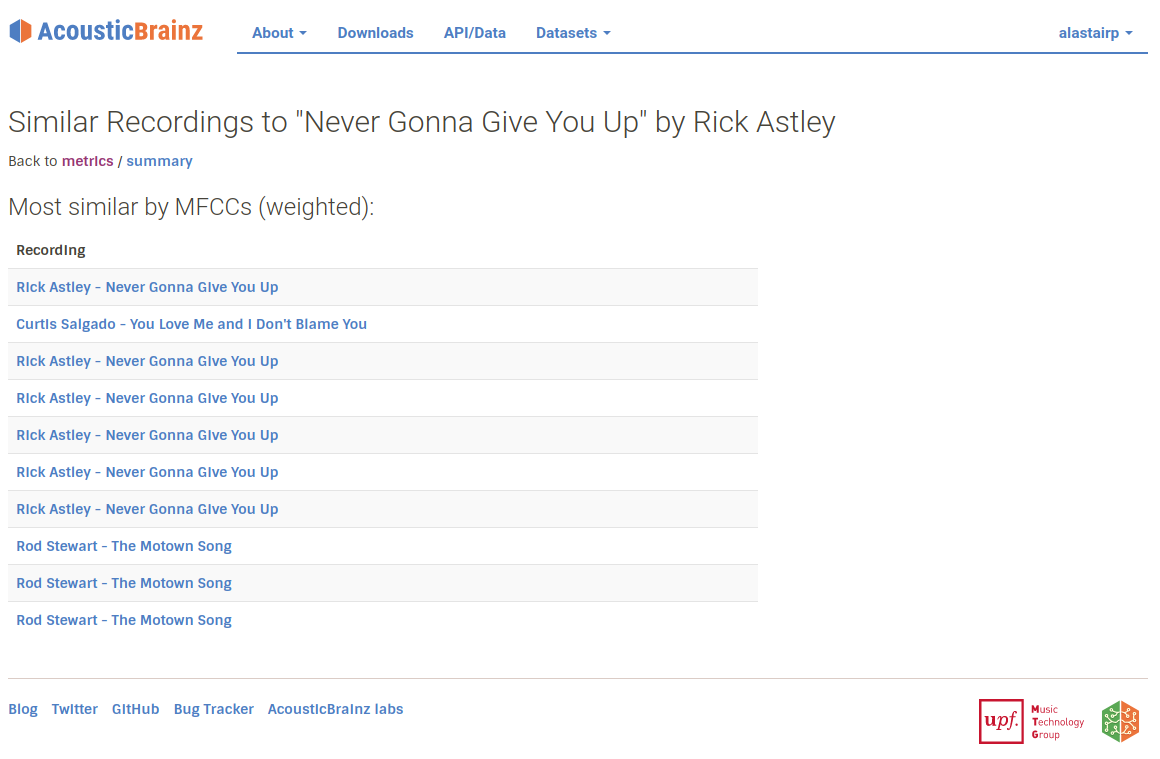
One thing that we can immediately see in these results is that the same recording appears many times. This is because AcousticBrainz stores multiple different submissions for the same MBID, and will sometimes get submissions for the same recording with different MBIDs if the data in MusicBrainz is like this. This is actually really interesting! It shows us that we are successfully identifying that two different submissions in AcousticBrainz as being the same using only acoustic information and no metadata. Using the API you can ask to remove these duplicated MBIDs from the results, and we have some future plans to use MusicBrainz metadata to filter more of these results when needed.
What’s next?
We haven’t yet performed a thorough evaluation of the quality of these similarity results. We’d like people to use them and give us feedback on what they think. In the future we may look at performing some user studies in order to see if some specific features tend to give results that people consider “more” similar than others. AcousticBrainz has a number of additional features in our database, and we’d like to experiment with these to see if they can be used as similarity metrics as well.
The fact that we can identify the same recording as being similar even when the MusicBrainz ID is different is interesting. It could be useful to use this similarity to identify when two recordings could be merged in MusicBrainz.
The data files used for this similarity are stand-alone, and can be used without additional data from AcousticBrainz or MusicBrainz. We’re looking at ways that we can make these data files downloadable so that developers can use them without having to query the AcousticBrainz API. If you think that you might be interested in this, let us know!
The 2019 MetaBrainz Summit took place on 27th–29th of September 2019 in Barcelona, Spain at the MetaBrainz HQ. The Summit is a chance for MetaBrainz staff and the community to gather and plan ahead for the next year. This report is a recap of what was discussed and what lies ahead for the community.
The Google Code-in is pretty much over for this time, and we’ve had a blast in our first year with the competition in MetaBrainz with a total of 116 students completing tasks. In the end we had to pick five finalists from these, and two of these as our grand prize winners getting a trip to the Googleplex in June. It was a really, really tough decision, as we have had an amazing roster of students for our first year. In the end we picked Ohm Patel (US) and Caroline Gschwend (US) as our grand prize winners, closely followed by Stanisław Szcześniak (Poland), Divya Prakash Mittal (India), and Nurul Ariessa Norramli (Malaysia). Congratulations and thank you to all of you, as well as all our other students! We’ve been very excited to work with you and look forwards to seeing you again before, during, and after coming Google Code-ins as well! 🙂
Indian student Rayne presenting MusicBrainz to her classmates.
In all we had 275 tasks completed during the Google Code-in. These tasks were divided among the various MetaBrainz projects as well as a few for beets. We ended up having 29 tasks done for BookBrainz, 124(!) tasks for CritiqueBrainz, 95 tasks for MusicBrainz, 1 task for Cover Art Archive, 6 tasks for MusicBrainz Picard, 3 tasks for beets, and 17 generic or MetaBrainz related tasks.
Some examples of the tasks that were done include:
A couple of YouTube introduction/tutorial videos. There are a couple more we didn’t make available yet, but a huge thanks to Caroline and JefftheBest for creating these!
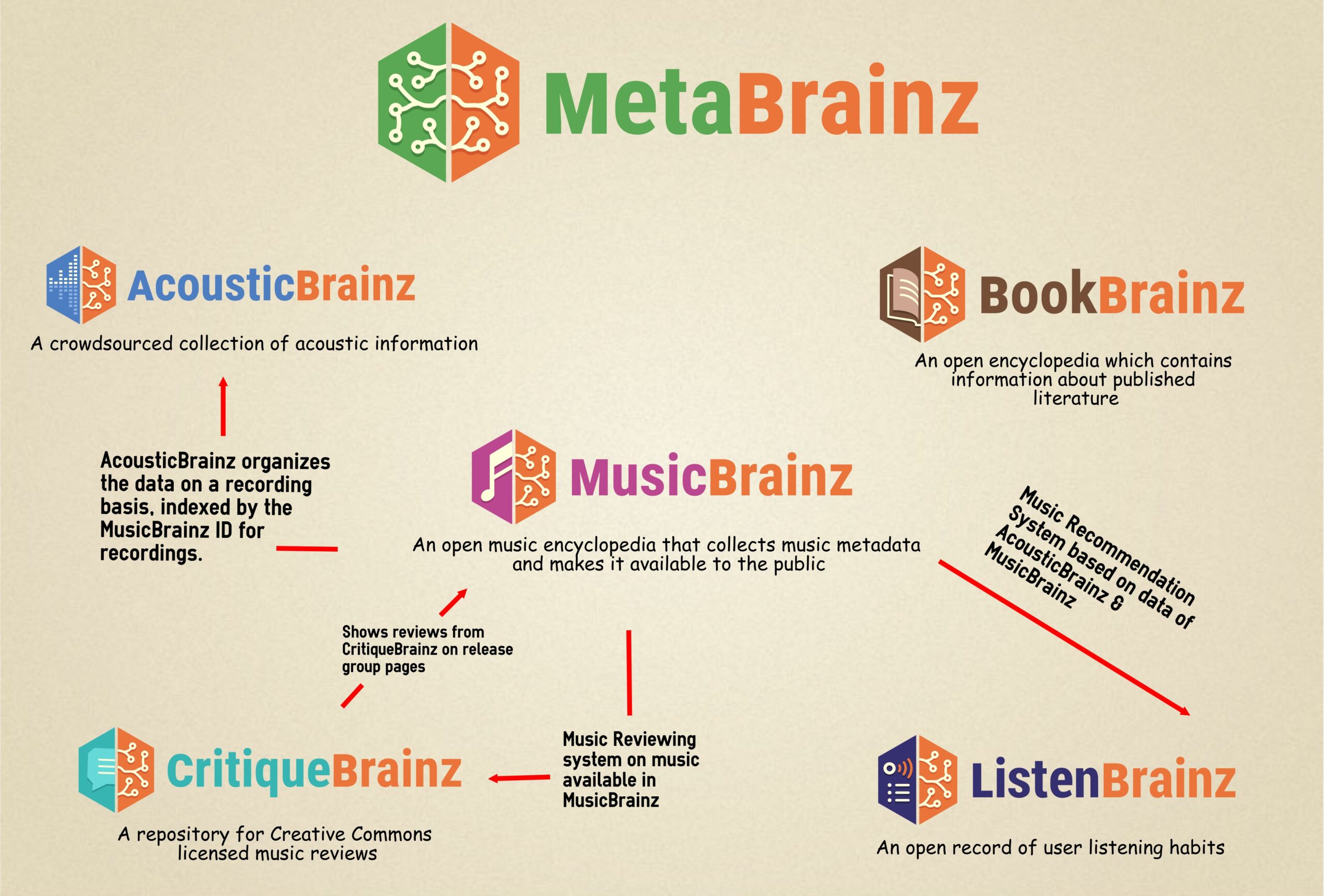
3 infographics were made to describe how the MetaBrainz projects relate to each other (see gallery below)
7 classroom presentations were held, spreading the word about open source, MetaBrainz, and MusicBrainz to young students around the world (pictures from a few of these in the gallery below)
In all, I’m really darn happy with the outcome of this Google Code-in and how some of our finalists continue to be active on IRC and help out. Stanisław is continuing work on BookBrainz, including having started writing a Python library for BB’s API/web service, and Caroline is currently working on a new icon set for the MusicBrainz.org redesign that can currently be seen at beta.MusicBrainz.org.
Again, congratulations to our winners and finalists, and THANK YOU! to all of the students having worked on tasks for MetaBrainz. It’s really been an amazing ride and we’re definitely looking forward to our next foray into Google Code-in!
Polish student Stanisław Szcześniak presenting about MusicBrainz.
Romanian student Borza Alex presenting MusicBrainz to his classmates.
Indian student Rayne presenting MusicBrainz to her classmates.