If you’re a prospective GSoC student who is hoping to apply with MetaBrainz this year, be sure to check out our guide to getting started and our currently suggested projects – but also note that we’d love for you to come up with your own suggestion! You may also want to take a look at the application template, which contains suggestions about
some of the things you should do and know before submitting your proposal.
For those of you who are already members of our community, you’re also welcome to add ideas to the suggestions page, and please be gentle when the GSoC hopefuls come along. 🙂
That’s really all for now, but expect to hear more about GSoC and our participation over the coming months!
The style of the website has changed to use our new logo and better match the rest of the *Brainz family. It may be rough around the edges in some areas, but we’ll continue to make improvements as we receive feedback. Thanks to Roman Tsukanov (Gentlecat) who did all of the initial work on this.
Other Changes
Nicolás Tamargo (reosarevok) has fixed our header menus to be clickable on touch devices, and we have some other fixes and improvements from Ulrich Klauer (chirlu) and myself listed below. The git tag for today’s release is v-2016-02-22.
Bug
[MBS-8007] – Can’t change collection type of existing collection
[MBS-8624] – Components for server-side rendering are not equivalent to TT macros
[MBS-8771] – Contact-URL on start page result in “Page Not Found”
[MBS-8772] – Big Audio Dynamite is high-lighted, but no open edits seem around
[MBS-8776] – JSON-formatted collection release list shows page total and not overall collection total
[MBS-8789] – “{user} has not tagged anything” in user/tags seems broken
[MBS-8801] – “A group of artists cannot have a gender” when removing the gender
Improvement
[MBS-739] – Menu items with dropdowns should not have actions under them (other than the drop down opening)
[MBS-6212] – No link to edit profile on the profile
The Google Code-in is pretty much over for this time, and we’ve had a blast in our first year with the competition in MetaBrainz with a total of 116 students completing tasks. In the end we had to pick five finalists from these, and two of these as our grand prize winners getting a trip to the Googleplex in June. It was a really, really tough decision, as we have had an amazing roster of students for our first year. In the end we picked Ohm Patel (US) and Caroline Gschwend (US) as our grand prize winners, closely followed by Stanisław Szcześniak (Poland), Divya Prakash Mittal (India), and Nurul Ariessa Norramli (Malaysia). Congratulations and thank you to all of you, as well as all our other students! We’ve been very excited to work with you and look forwards to seeing you again before, during, and after coming Google Code-ins as well! 🙂
Indian student Rayne presenting MusicBrainz to her classmates.
In all we had 275 tasks completed during the Google Code-in. These tasks were divided among the various MetaBrainz projects as well as a few for beets. We ended up having 29 tasks done for BookBrainz, 124(!) tasks for CritiqueBrainz, 95 tasks for MusicBrainz, 1 task for Cover Art Archive, 6 tasks for MusicBrainz Picard, 3 tasks for beets, and 17 generic or MetaBrainz related tasks.
Some examples of the tasks that were done include:
A couple of YouTube introduction/tutorial videos. There are a couple more we didn’t make available yet, but a huge thanks to Caroline and JefftheBest for creating these!
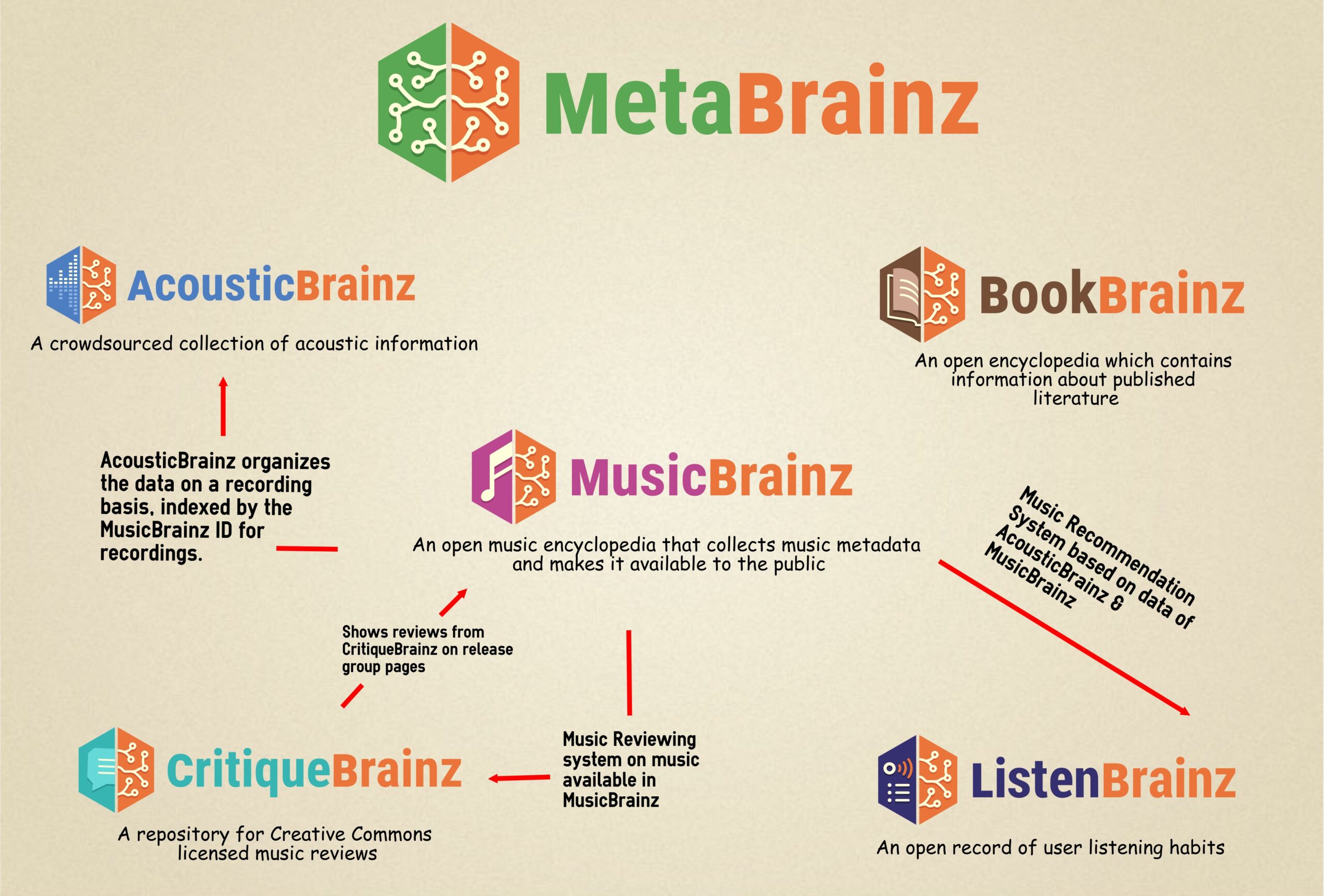
3 infographics were made to describe how the MetaBrainz projects relate to each other (see gallery below)
7 classroom presentations were held, spreading the word about open source, MetaBrainz, and MusicBrainz to young students around the world (pictures from a few of these in the gallery below)
In all, I’m really darn happy with the outcome of this Google Code-in and how some of our finalists continue to be active on IRC and help out. Stanisław is continuing work on BookBrainz, including having started writing a Python library for BB’s API/web service, and Caroline is currently working on a new icon set for the MusicBrainz.org redesign that can currently be seen at beta.MusicBrainz.org.
Again, congratulations to our winners and finalists, and THANK YOU! to all of the students having worked on tasks for MetaBrainz. It’s really been an amazing ride and we’re definitely looking forward to our next foray into Google Code-in!
Polish student Stanisław Szcześniak presenting about MusicBrainz.
Romanian student Borza Alex presenting MusicBrainz to his classmates.
Indian student Rayne presenting MusicBrainz to her classmates.
We’re slowly approaching that time of year: Schema change release time. After skipping our fall update to focus on some internal tasks, we’re ready to have another schema change release in the spring: May 16, 2016
We have started the process to collect features we wish to release for this schema change release and we’ll be publishing that list in the coming weeks. However, we’re contemplating the impact of one more change we’d like to make: Upgrading to a more recent version of Postgres.
Internally we are going upgrade to Postgres 9.5, which was recently released, so we expect that the Postgres team will have worked out the most significant kinks before we’re ready to move to it. However, even though we are moving to 9.5, we are considering the impact on our downstream users/customers who need to make the same or similar change.
While we are moving to version 9.5 of Postgres, we have the option of only adopting features from Postgres 9.4, which means that our downstream users may continue to use Postgres 9.4. However, Postgres 9.5 has some nice features we’d like to use (e.g. UPSERT), so we’re pondering if it is possible for us to require Postgres 9.5 from all of ours Live Data Feed users starting on May 16, 2016.
We have already informally queried a few of ours users and so far it seems that requiring Postgres 9.5 is feasible. If you are a Live Data Feed user and feel that this requirement of Postgres 9.5 is too much for your and your organization by May 16, 2016, please leave a comment to this blog post!
Welcome, readers, to the first blog post from the BookBrainz team! I’m Ben (AKA LordSputnik), one of the two guys leading the BookBrainz project to create the most complete and thorough database of literature in the world. Or, in other words, doing for books what MusicBrainz does for music. In this post, I’m going to talk to you about the February 2016 release of BookBrainz, what we’ve been working on, and the current direction of the project.
Unit Testing
One of the biggest areas of work in this update is the new unit testing for the web service. Unit testing allows us to check that our functions work as we expect them to, and help to find and prevent bugs in the code. This is something we’ve been pushing back for months now, and it really needed doing. Luckily, the Google Code-in (GCI) happened, and one of our students, Stanisław Szcześniak, stepped up to the challenge of writing our test suite.
4000 lines of code and several test classes later, our test coverage (the proportion of web service code checked by the tests) has increased from 40% to 70%, and we’ve found about 10 bugs which we’ll be fixing for the next release. Stanisław is still helping out, now focusing his efforts on a BookBrainz plugin for Calibre (like Picard, but for eBooks) and the new BookBrainz client library.
Python Client Library
We’re planning the Python client library to be a key component of a couple of applications we’ll be writing in the future to increase the amount of data in BookBrainz. It’ll also allow outside developers to programmatically access and modify the information in BookBrainz through our web service. At the moment, it’s still in the early stages of development, with Stanisław playing about to find a clean and elegant architecture.
Reactification!
Another area we’re continuing to look into is changing our existing web page templates (written in Jade) to use the React JavaScript library. This helps us by allowing the same code to be used for templating in the browser and the server, and also allows us to use third-party libraries to simplify our user interface code (for example, React-Bootstrap and React-fontawesome).
So far, we’ve converted 9 pages, including login, registration, search and revision display, with a little help from our GCI students. An added benefit of this is that we’ve been able to apply the idea of progressive enhancement to allow JS-enabled browsers to refresh search results in real-time, while keeping the previous functionality for older or limited browsers.
Browser Compatibility
Since the last release, we’ve established a list of supported browsers, and signed up to a really useful automated test site called BrowserStack. This allows us to get screenshots of key pages of the site in many different browsers, and see where things are breaking. Although we’ve been mainly been working on back-end code for the last couple of months, there are a few issues that we’ve found out about in older browsers which will hopefully be fixed soon™. If there are any issues that you’ve spotted when using the site, be sure to let us know in the BookBrainz JIRA.
Improving Error Messages
Working on how we display errors to users is another front-end issue that we’ve sadly been neglecting for about half a year now, in favor of improving the back-end. A good example of the problem is logging in – right now, the site sometimes displays a vague error message about not being able to log the user in, and sometimes it spits out the really unhelpful message “Internal Server Error”.
So informative, BookBrainz…
Part of the work we’ll be doing on error messages in the next few months will involve creating custom error pages and trying to eliminate unfriendly technical error messages. Giving the user a better idea of what to do when something does go wrong is also important, and we’ll be trying to achieve this along with making error display more consistent across the site.
Direct Database Access
The largest change we’ve been working on over the last couple of months is having the site access the database directly, rather than obtaining data through the web service, as we’ve been doing up until now. Originally, we decided to put the web service in between the site and database to ensure that the web service had good data editing functionality and that data representations were the same as those in the site.
However, this led to us having to effectively define our schema three times – once in the database, once for structuring web service data, and once to define the data models used in the site code. We found this to be a bad situation, because it’s easy to forget to keep the three schemas consistent. Last autumn, I tried to improve the web service to automatically generate web service data structures from the site data models, but eventually decided that this would be overly complex and time-consuming.
Instead, we made the decision to migrate all of our code to Node.js, currently used by the site, and then use a shared data model package for both the site code and web service code. With this change, we would only have to define the schema twice – once in the database, and once in JavaScript – better, but not ideal. Thankfully, the Node.js library bookshelf provides database reflection, which means that we can automatically generate the Node.js data models from the database schema, finally removing the need to define the schema in multiple places.
Now, we’re about two-thirds of the way through updating the site to use the new data models – you can see our progress in the GitHub repository. Due to a new emphasis on code quality and implementing tests as we go along, progress has been slow but steady, but this should hopefully result in a more stable site when we complete this upgrade within the next couple of months.
New Web Service
Following the direct database site update, our schema will have changed in subtle ways which will make it impossible to keep using the existing web service code. Ideally, we would have kept the schema unchanged while we moved to Node.js, but partly due to ORM limitations and partly due to a desire to make things better, we’ve been tinkering with it as we’ve gone along.
This means that the web service will be unavailable for a few months while we rewrite it in Node.js. However, the new web service should be a big improvement on the old one, with a more carefully planned design learning from the mistakes of the current iteration. If you have any suggestions for what you think would be a good feature for the new web service, please let us know in the comments!
That’s it from me for now. I hope you’ve found it interesting to get an insight into the things we’ve been working on! For a more specific list of changes in the February 2016 release, please see our change log. If you have any suggestions for our future blog posts, I’d love to hear your feedback.
This update hopefully fixes some issues with “Edit Medium” edits that, in rare cases, resulted in an incorrect track listing. Sometimes tracks were being inexplicably deleted. The git tag for today’s release is v-2016-02-08.
Bug
[MBS-8752] – Database inconsistencies when updating medium
[MBS-8765] – instrument_annotation should not be backed up in mbdump.tar.bz2