Hi, this is Prathamesh Ghatole (IRC Nick: “Pratha-Fish”), and I am an aspiring Data Engineer from India, currently pursuing my bachelor’s in AI at GHRCEM Pune, and another bachelor’s in Data Science and Applications at IIT Madras.
I had the pleasure to be mentored by alastairp and the rest of the incredible team at the MetaBrainz Foundation. Throughout this complicated but super fun project as a GSoC ‘22 contributor! This blog is all about my journey over the past 18 weeks.
We created AcousticBrainz 7 years ago and started to collect data with the goal of using that data down the road once we had collected enough. We finally got around to doing this recenty, and realised that the data simply isn’t of high enough quality to be useful for much at all.
We spent quite a bit of time trying to brainstorm on how to remedy this, but all of the solutions we found require a significant amount of money for both new developers and new hardware. We lack the resources to commit to properly rebooting AcousticBrainz, so we’ve taken the hard decision to end the project.
Read on for an explanation of why we decided to do this, how we will do it, and what we’re planning to do in the future.
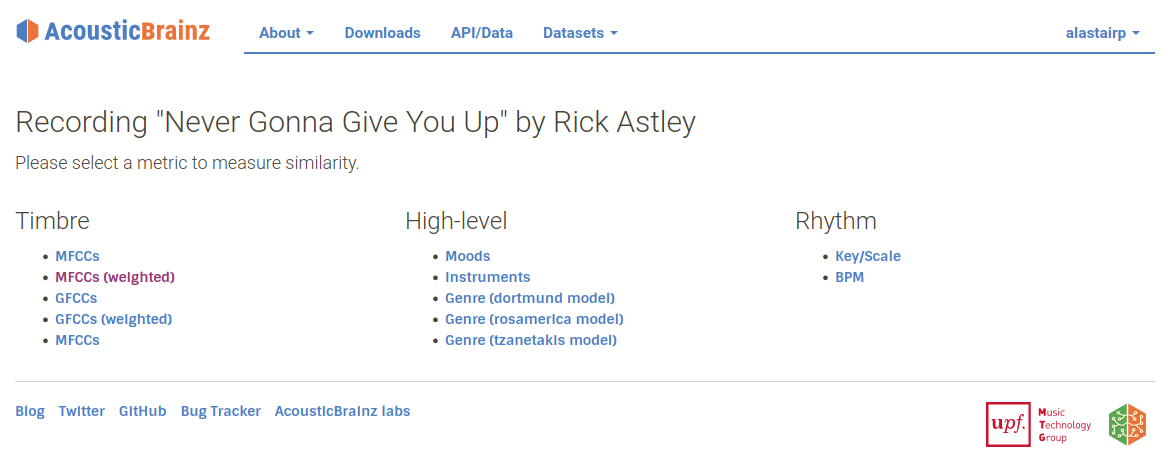
We’re pleased to announce that we have just released acoustic similarity in AcousticBrainz. Acoustic similarity is a technique to automatically identify which recordings sound similar to other recordings, using only the recordings themselves, and not any additional metadata. This feature is available via the AcousticBrainz API and the AcousticBrainz website, from any recording page. General documentation on acoustic similarity is available at https://acousticbrainz.readthedocs.io/similarity.html.
This feature is based on work started by Philip Tovstogan at the Music Technology Group, the research group that provides the essentia feature extractor that powers AcousticBrainz. The work was continued by Aidan Lawford-Wickham during Summer of Code 2019. Thanks Philip and Aidan for your work!
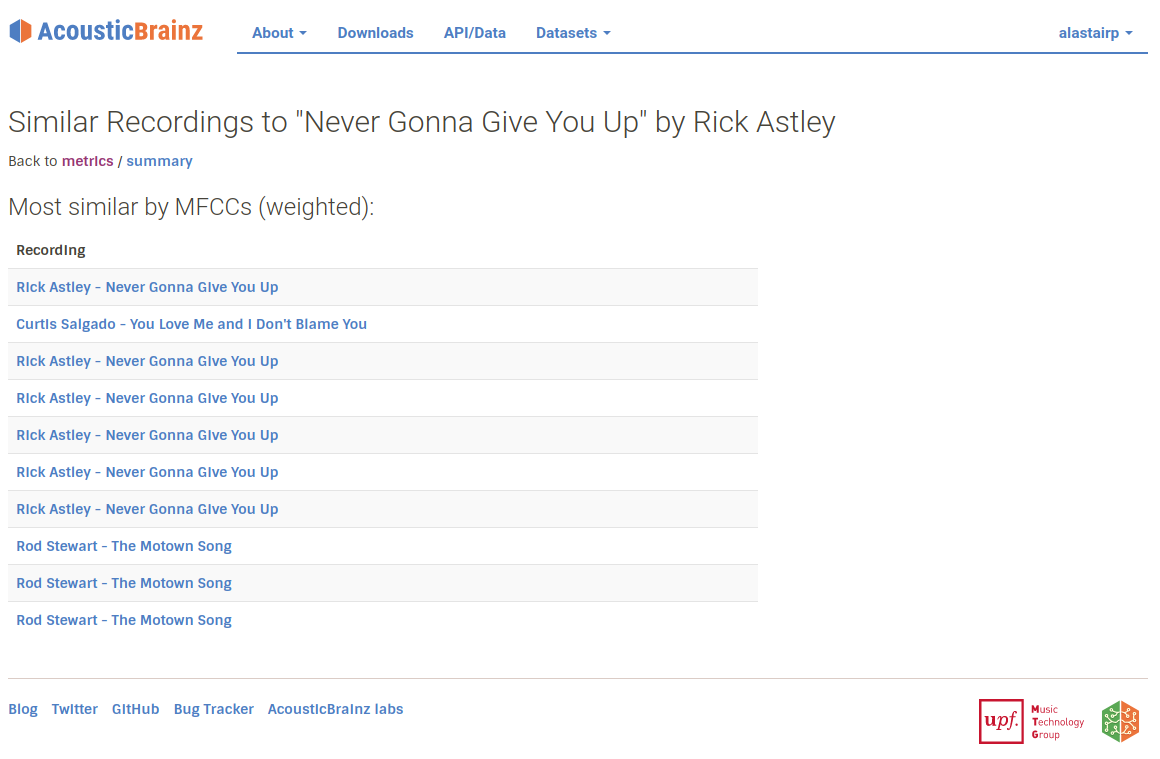
From the recording view on AcousticBrainz, you can choose to see similar recordings and choose which similarity metric you want to use. Then, a list of recordings similar to the initial recording will be shown.
These metrics are based on different musical features that the AcousticBrainz feature extractor identifies in the audio file. Some of these features are related to timbral characteristics (generally, what something sounds like), Rhythmic (related to tempo or perceived pulses), or AcousticBrainz’s high-level features (hybrid features that use our machine learning system to identify features such as genre, mood, or instrumentation).
One thing that we can immediately see in these results is that the same recording appears many times. This is because AcousticBrainz stores multiple different submissions for the same MBID, and will sometimes get submissions for the same recording with different MBIDs if the data in MusicBrainz is like this. This is actually really interesting! It shows us that we are successfully identifying that two different submissions in AcousticBrainz as being the same using only acoustic information and no metadata. Using the API you can ask to remove these duplicated MBIDs from the results, and we have some future plans to use MusicBrainz metadata to filter more of these results when needed.
What’s next?
We haven’t yet performed a thorough evaluation of the quality of these similarity results. We’d like people to use them and give us feedback on what they think. In the future we may look at performing some user studies in order to see if some specific features tend to give results that people consider “more” similar than others. AcousticBrainz has a number of additional features in our database, and we’d like to experiment with these to see if they can be used as similarity metrics as well.
The fact that we can identify the same recording as being similar even when the MusicBrainz ID is different is interesting. It could be useful to use this similarity to identify when two recordings could be merged in MusicBrainz.
The data files used for this similarity are stand-alone, and can be used without additional data from AcousticBrainz or MusicBrainz. We’re looking at ways that we can make these data files downloadable so that developers can use them without having to query the AcousticBrainz API. If you think that you might be interested in this, let us know!
Just in time for Christmas we are pleased to announce a new feature in our most recent release of ListenBrainz, the ability to create and share your own playlists! We created two playlists for each user who used ListenBrainz containing music that you listened to in 2020. Check out your lists at https://listenbrainz.org/my/recommendations. Read on for more details…
With our continuing work on using data in ListenBrainz to generate recommendations, we realised that we needed a place to store lists of music. That sounded like playlists to us, so we added them to ListenBrainz. As always, we did this work in the public ListenBrainz repository. You can now create your own playlists with the web interface or by using the API. Recordings in playlists map to MusicBrainz identifiers. If you’re trying to add something and can’t find it, make sure that it’s in MusicBrainz first.
Once you have a playlist, you can listen to it using our built-in BrainzPlayer, or export it to Spotify if you have an account there. If you have already linked your Spotify account to ListenBrainz you may have to re-authenticate and give us permission to create playlists on your behalf. Playlists can also be exported in the open JSPF format using the ListenBrainz API.
Over the last year we’ve started thinking about how to use data in MetaBrainz projects to generate recommendations of new music for people to listen to. For this reason, we started the Troi recommendation framework. This python package allows developers to build pipelines that take data from different sources and combine it in order to generate recommendations of music to listen to. We have already developed data sources using MusicBrainz, ListenBrainz, and AcousticBrainz. If you are a developer interested in working on recommendations in the context of ListenBrainz we encourage you to check it out.
Now that we can store playlists we needed some content to fill them with. Luckily we have some great projects worked on by students over the last few years as part of MetaBrainz’ participation in the Google Summer of Code project, including this year’s work on statistics and summary information by Ishaan. Using Troi and ListenBrainz statistics, we got to work. Every user who has been contributing data to ListenBrainz recently now has two brand new 2020 playlists based on the top recordings that you listened to in 2020 and the recordings that you first listened to in 2020. If you’re interested in the code behind these playlists, you can see the code for each (top tracks, first tracks) in the troi repository.
If you’re a long-time user of ListenBrainz you may be familiar with the problem of matching your listens to content in MusicBrainz to be able to do things with it. We’ve been working hard on a solution to this problem and have built a new tool using typesense to provide a quick and easy way to search for items in the MusicBrainz database. You are using this tool when you create a playlists using the web interface and search for a recording to add. This is still a tech preview, but in our experience it works really well. Thanks to the team at typesense for helping us with our questions over the last few weeks!
This work is still in its early days. We thought that this was such a great feature that we wanted to get it out in front of you now. We’re happy to take your feedback, or hear if you are having any problems. Open a ticket on our bug tracker, come and talk to us on IRC, or @ us. Did we give you a bad jam? Sorry about that! We’d love to have a conversation about what went well and what didn’t in order to improve our systems. In 2021 we will start generating weekly and daily playlists for users based on your recent listens using our collaborative filtering recommendations system.
We had an in-person meeting at the MTG during the MetaBrainz summit to discuss the status and future of AcousticBrainz. We came up with a rough outline of things that we want to work on over the next year or so. This is a small list of tasks that we think will have a good impact on the image of AcousticBrainz and encourage people to use our data more.
State of AcousticBrainz
AcousticBrainz has a huge database of submissions (over 10 million now, thanks everyone!), but we are currently not using the wealth of data to our advantage. For the last year we’ve not had a core developer from MetaBrainz or MTG working on existing or new features in AcousticBrainz. However, we now have:
Param, who is including AcousticBrainz in his role with MetaBrainz
Philip, who is starting a PhD at MTG, focused on some of the algorithms/data going into AcousticBrainz
Alastair, who now has more time to put towards management of the project
Because of this, we’re glad to present an outline of our next tasks for AcousticBrainz:
Short-term
Some small tasks that are quick to finish and we can use to show off uses of the data in AcousticBrainz
Merge Philip’s similarity, including an API endpoint
Philip’s masters thesis project from last year uses PostgreSQL search to find acoustically similar recordings to a target recording. This uses the features in AcousticBrainz. We need to ensure that PostgreSQL can handle the scale of data that we have.
An extension of this work is to use the similarity to allow us to remove bad duplicate submissions (we can take all recordings with the same MBID and see if they are similar to each other, if one is not similar we can assume that it’s not actually the same as the other duplicates, and mark it as bad). We want to make these results available via an API too, so that others can check this information as well.
Merge Existing PRs
We have many great PRs from various people which Alastair didn’t merge over the last year. We’re going to spend some time getting these patches merged to show that we’re open to contributions!
Publish our Existing models
In research at MTG we’ve come up with a few more detailed genre models based on tag/genre data that we’ve collected from a number of sources. We believe that these models can be more useful that the current genre models that we have. The AcousticBrainz infrastructure supports adding new models easily, so we should spend some time integrating these. There are a few tasks that need to be done to make sure that these work
Ensure that high-level dumps will dump this new data (If we have an existing high-level dump we need to make a new one including the new data)
Ensure that we compute high-level data for all old submissions (we currently don’t have a system to go back and compute high-level data for old submissions with a new model, the high-level extractor has to be improved to support this)
Update/fix some pages
We have a number of issues reported about unclear text on some pages and grammar that we can improve. Especially important are
Front page (Show off what we have in the project in more detail, instead of just a wall of text)
Data page (instead of just showing tables of data, try and work out a better way of presenting the information that we have)
Fix Picard plugin
When AB was down during our migration we were serving HTML from our API pages, which caused Picard to crash if the AB plugin was enabled while trying to get AB data. This should be an easy fix in the Picard plugin.
High Impact
These are tasks that we want to complete first, that we know will have a high impact on the quality of the data that we produce.
Frame-level data
We want to extract and store more detailed information about our recordings. This relies on working being done in MTG to develop a new extractor to allow us to get more detailed information. It will also give us other improvements to data that we have in AB that we know is bad. This data is much bigger than our current data when stored in JSON (hundreds of times larger), so we need to develop a more efficient way of storing submissions. This could involve storing the data in a well-known binary data exchange format. A bunch of subtasks for this project:
Finish the essentia extractor software
Decide on how to store items on the server (file format, store on disk instead of database)
Work out a way to deal with features from two versions of the extractor (do we keep accepting old data? What happens if someone requests data for a recording for which we have the old extractor data but not the new one?)
Upgrade clients to support this (Change to HTTPS, change to the new API URL structure, ensure that clients check before submission if they’re the latest version, work out how to compress data or perform a duplicate check before submission)
Deduplication (If we have much larger data files, don’t bother storing 200 copies for a single Beatles song if we find that we already have 5-10 submissions that are all the same)
MusicBrainz Metadata
Rashi’s GSoC project in 2018 helped us to replicate parts of the MusicBrainz database into AcousticBrainz. This allows us to do amazing things like keep up-to-date information about MBID redirects, and do search/browse/filtering of data based on relationships such as Artists just by making a simple database query. We want to merge this work and start using it.
Dumps
When we changed the database architecture of AcousticBrainz in 2015 we stopped making data dumps, making people rely on using the API to retrieve data. This is not scalable, and many people have asked for this data. We want to fix all of the outstanding issues that we’ve found in the current dumps system and start producing periodic dumps for people to download.
Build more models
In addition to the existing models that we’ve already built (see above, “Publish our Existing models”), we have been collecting a lot of metadata that we could use to make even more high-level models which we think will have a value in the community. Build these models and publicly release them, using our current machine learning framework.
Wishlist
These are tasks that we want to complete that will show off the data that we have in AcousticBrainz and allow us to do more things with the data, but should come after the high-impact tasks.
Expose AB data on MusicBrainz
As part of the process to cross-pollinate the brainz’s, we want to be able to show a small subset of AB data that we trust on the MB website. This could include information such as BPM, Key, and results from some of our high-level models.
Improve music playback
On the detail page for recordings we currently have a simple YouTube player which tries to find a recording by doing text search. We want to improve the reliability and functionality of this player to include other playback services and take advantage of metadata that we already have in the MusicBrainz database.
Scikit-learn models
The future of machine learning is moving towards deep learning, and our current high-level infrastructure written in the custom Gaia project by MTG is preventing us from integrating improved machine learning algorithms to the data that we have. We would like to rewrite the training/evaluation process using scikit-learn, which is a well known Python library for general machine learning tasks. This will make it easier for us to take advantage of improvements in machine learning, and also make our environment more approachable to people outside the MusicBrainz community.
Dataset editor improvements
Part of the high-level/machine learning process involves making datasets that can be used to train models. We have a basic tool for building datasets, however it is difficult to use for making large datasets. We should look into ways of making this tool more useful for people who want to contribute datasets to AcousticBrainz.
Search
With the integration of the MusicBrainz database into AcousticBrainz, we will be able to let people search for metadata related to items which we know only exist in AcousticBrainz. We think that this is a good way for people to explore the data, and also for people to make new datasets (see above). We also want to provide a way that lets people search for feature data in the database (e.g. “all recordings in the key of Am, between 100 and 110BPM”).
API updates
As part of the 2018 MetaBrainz summit we decided to unify the structure of the APIs, including root path and versioning. We should make AcousticBrainz follow this common plan, while also supporting clients who still access the current API.
We should become more in-line with the MetaBrainz policy of API access, including user-agent reporting, rate limiting, and API key use.
Request specific data
Many services who use the API only need a very small bit of information from a specific recording, and so it’s often not efficient to return the entire low-level or high-level JSON document. It would be nice for clients to be able to request a specific field(s) for a recording. This ties in with the “Expose AcousticBrainz data on MusicBrainz” task above.
Everything else
Fix all our bugs and make AcousticBrainz an amazing open tool for MIR research.
Thanks for reading! If you have any ideas or requests for us to work on next please leave a comment here or on the forums.
After more than 2 years we’ve finally released version 0.6 of python-musicbrainzngs, a library for accessing the Musicbrainz webservice from python.
After such a long time we have perhaps too many new changes to describe. Some major changes include:
Better handling of authentication private user collections
Support for loading all types of user collections (artist, event, place, recording, release, work)
Work attributes
Support for the Cover Art Archive
Support for Events, Instruments, Places, and Series
And numerous other bug fixes and small changes. See the CHANGES file for more information.
This release contains contributions by Alastair Porter, Corey Farwell, Ian McEwen, Jérémie Detrey, Johannes Dewender, Pavan Chander, Rui Gonçalves, Ryan Helinski, Shadab Zafar, and Wieland Hoffmann. Thank you everyone!
The new version can be downloaded from github, pypi, or installed with pip
It’s been over a year since we last posted about AcousticBrainz, but a lot of work has been going on in the background. This post will give an overview about some of the things that we’ve achieved in the last year.
Data contributions
Our last blog post was neatly titled “What do 650,000 audio files look like, anyway?” Back then, we thought that this was a lot of submissions. Little did we know… I’m glad to report that we now have over 3.5 million submissions, of which almost 2 million are for unique MBIDs. This is a great contribution and we’d like to thank everyone who submitted data to us.
Dataset and model building
MusicBrainz coder Gentlecat returned to participate in Google Summer of Code last year and developed a new tool to let us create datasets and create new computational models. We’re really excited about how this can allow community members to help us increase the quality of the semantic information we provide in AcousticBrainz. We will make another blog post soon explaining how it works.
We presented an academic overview of AcousticBrainz (PDF) at the 16th International Society for Music Information Retrieval (ISMIR) conference in Malaga, Spain. The feedback from the academic community was very encouraging. Many people were interested in the data and wanted to know what they could do with it. We hope that there will be some new projects announced using the data at this year’s conference.
Integration with other data sources
MusicBrainz and AcousticBrainz don’t exist in a vacuum. One important thing that we need to make sure we do is interact with other researchers and products in the same field. To that end, we started AcousticBrainz Labs, a showcase of some of the experiments that we’re working on in AcousticBrainz. The first thing we have published is a mapping between AcousticBrainz and the Million Song Dataset, that we hope people will use to compare these two datasets.
Database upgrades and Data format changes
We’ve just upgraded to PostgreSQL 9.5 (from 9.3), which allows us to use the new jsonb datatype introduced in PostgreSQL 9.4. This change lets us store feature data more efficiently. We also made some changes to the database schema to let us start creating new data from datasets and computation models.
One result of this is that we are creating a new complete data dump, and stopping the old incremental dumps. We are also taking the opportunity to automate this incremental dump process, which is something that a number of people have asked for.
Another change is that the format of the high level JSON data is changing. This is to better reflect some of the complexities that exist in hosting such a large and varied dataset.
Contribute to AcousticBrainz development
We’re always interested in help from other people to contribute data, code, and ideas to AcousticBrainz. Once again, MetaBrainz is participating in Google’s Summer of Code, and AcousticBrainz is a possible project to work on. If you’re not a student you’re still welcome to work with us.
Hot on the heels of our release of the first 650,000 feature files as part of the first release of AcousticBrainz, we are presenting some initial findings based on this dataset.
We thank Emilia Gómez (@emiliagogu), an Associate Professor and Senior Researcher at the Music Technology Group at Universitat Pompeu Fabra for doing this analysis and sharing her results with us. All of these results are based on data automatically computed by our Essentia audio analysis system. Nothing was decided by people. Isn’t that cool?
The MTG recently started the AcousticBrainz http://acousticbrainz.org/ project, in collaboration with MusicBrainz. Data collection started on September 10th, 2014, and since then a total of 656,471 tracks (488,658 unique ones) have been described with essentia. I have been working for a while with audio descriptors and I followed the porting some of my algorithms to essentia, especially chroma features and key estimation. For that reason, I was curious to get a look this data. I present here some basic statistics. I computed them with the SPSS statistical software.
WHICH KIND OF MUSICAL GENRES DO WE HAVE IN THE COLLECTION?
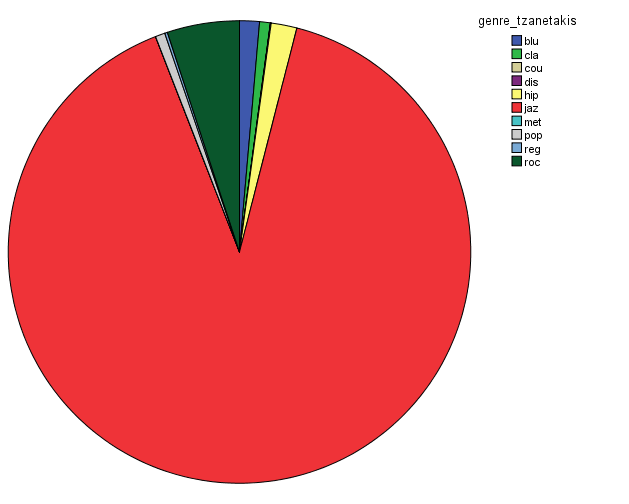
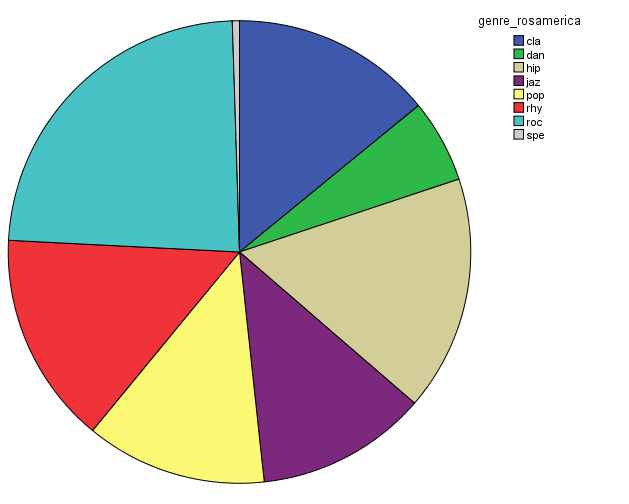
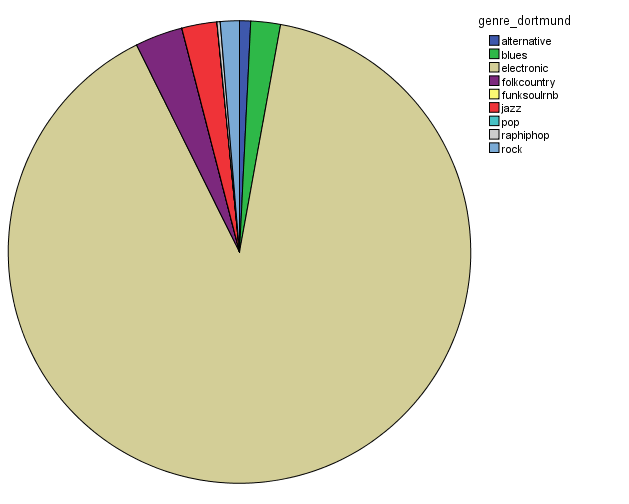
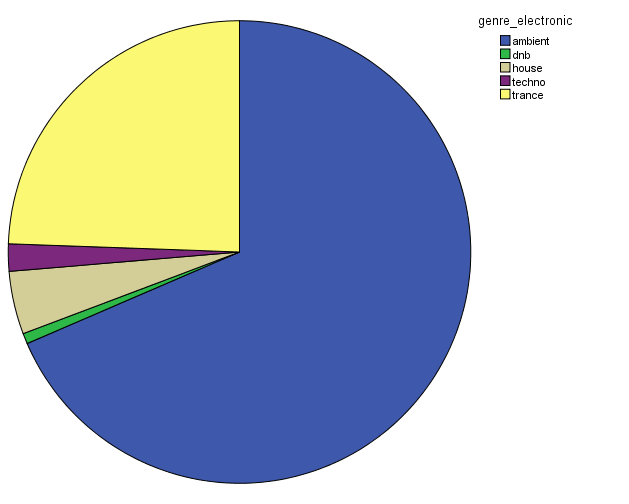
In order to characterize this dataset, I first thought about genre. In essentia, there are four different genre models: trained on the data by Tzanetakis (2001), another one compiled at the MTG (Rosamerica), Dortmund and a database of Electronic music. Far from providing information on the kind of musical genres, these models seem to be contradictory! For example, in the Tzanetakis dataset “jazz” seems to be the most estimated genre, while the proportion of jazz excerpts is very small in the other models.
Genre estimations using the Tzanetakis dataset
Genre estimations using the Rosamerica dataset
Genre estimations using the Dortmund dataset
Genre estimations using the Electronic dataset
So in conclusion, we have a lot of jazz (according to the Tzanetakis dataset), electronic music (according to the Dortmund dataset), ambient (according to electronic dataset) and an equal distribution of all generes Rosamerica dataset (which does not include a category for electronic music)….Not very clarifying then! This is definitely something that we will be looking at in more depth.
WHAT ABOUT MOOD THEN?
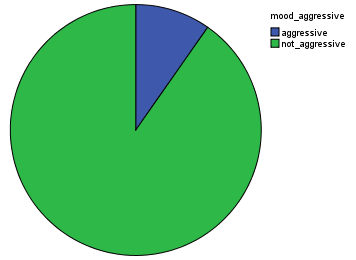
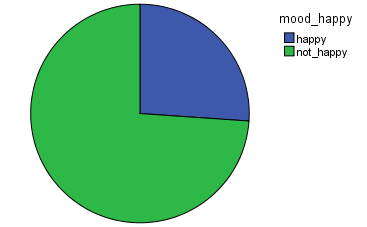
For Mood characterization, 5 different binary models were trained and computed on the dataset. We observe that there is a larger proportion of non-acoustic music, non-aggressive, and electronic. It is nice to see that most of the music is not happy and not sad! From this and previous study, I would then conclude that there is a tendency in the AcousticBrazinz dataset for electronic music.
Distribution of accoustic and non-accoustic (e.g. electronic) music
How aggressive our dataset is
The amount of electronic music (compare with the acoustic graph above)
…and if the music is happy or not
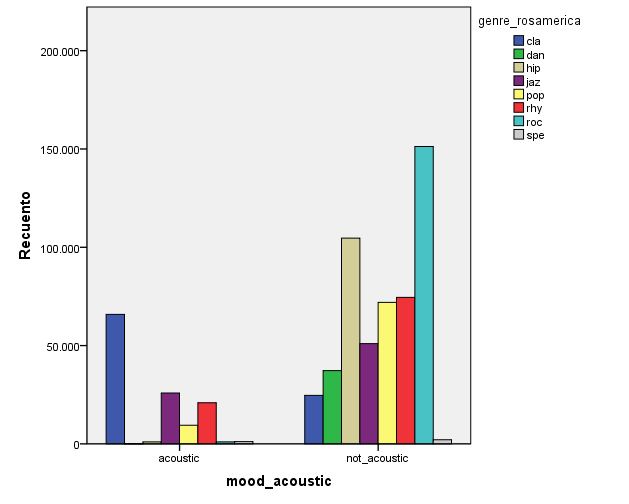
If we check for genre vs mood interactions, there are some interesting findings. We find that Classical is the most acoustic genre and rock is the least acoustic genre (due to its inclusion of electronic instruments):
How much music in each genre is accoustic or not
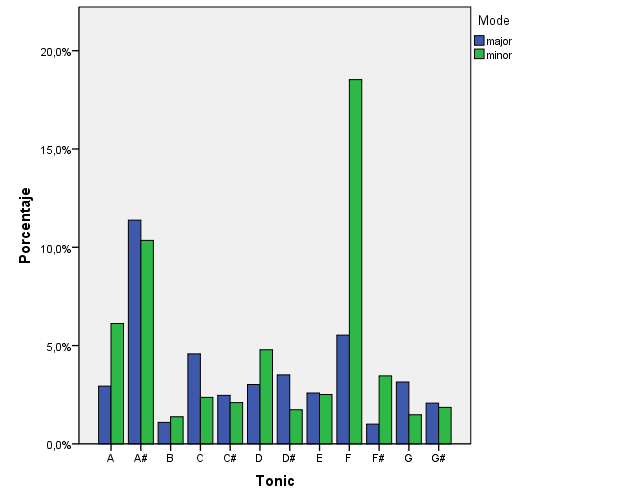
HOW IS KEY ESTIMATION WORKING?
From a global statistical analysis, we observe that major and minor modes are both represented, and that the most frequent key is F minor / Ab Major or F# minor / A Major. This seems a little strange; A major and E major are very frequent keys in rock music. Maybe there are some issues with this data that need to be looked at.
The keys and modes of the tracks in the database
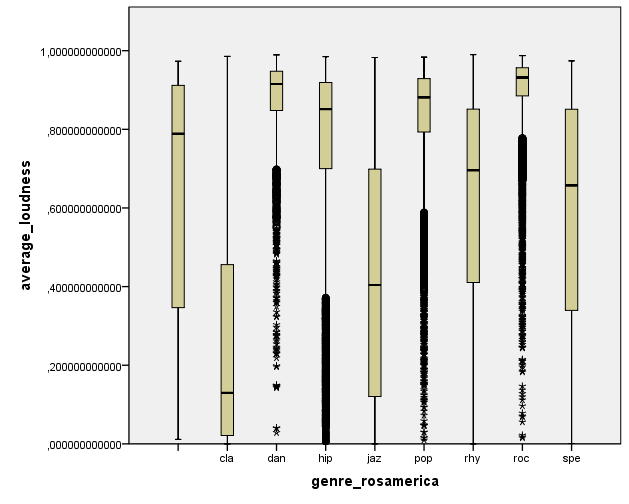
IS THERE A LINK BETWEEN FEATURES AND GENRE?
I wanted to do some plots on acoustic features vs genres. For example, we observe a small loudness level for classical (cla) music and jazz (jaz), and a high one for dance (dan), hip hop (hip), pop, and rock (roc).
The loudness of songs by genre
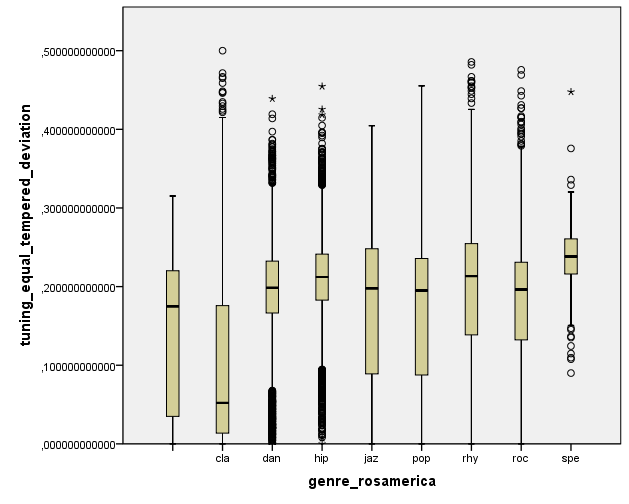
Finally, it is nice to see the relation between equal-tempered deviation and musical genre. This descriptor measures the deviation of spectral peaks with respect to equal-tempered tuning. It’s a very low-level feature but it seems to be related to genre. It is lower for classical music than for other musical genres.
Variation from equal‐tempered tuning per genre
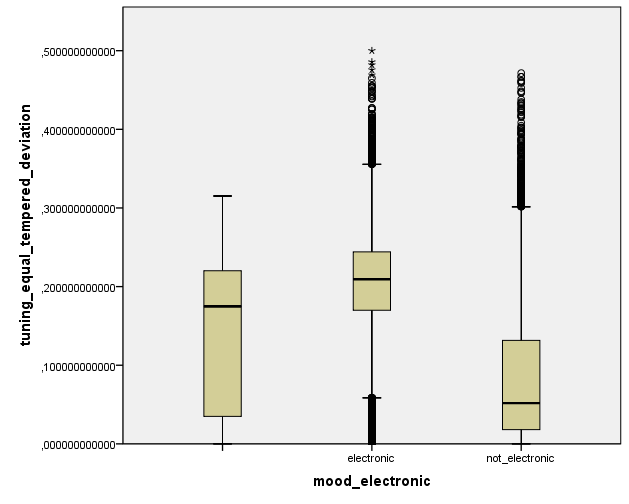
We also observe that for electronic music, equal tempered deviation is higher than for non-electronic music/acoustic music. What does this mean? In simple terms, it seems that electronic music tends to ignore the rules of what it means to be “in tune” more than what we might term “more traditional” music.
Variation from equal‐tempered tuning for songs reported as electronic/non-electronic
IS THERE A LINK BETWEEN FEATURES AND YEAR?
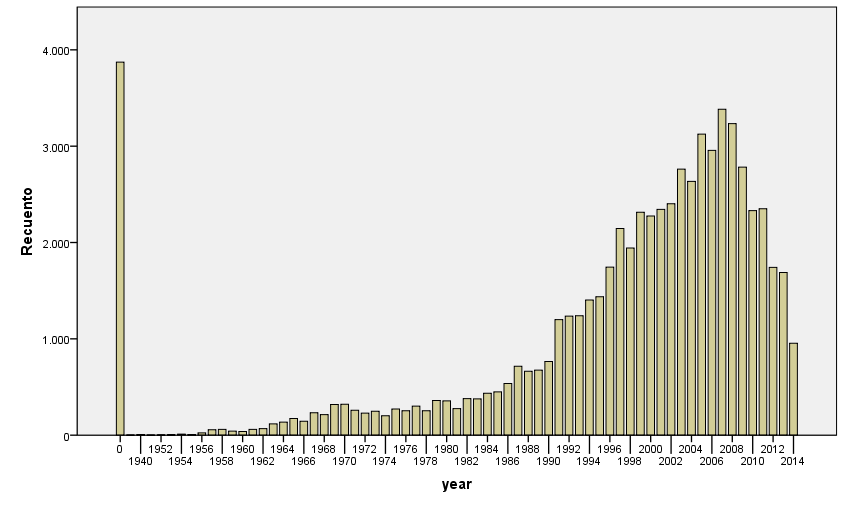
I was curious to check for historical evolution in some acoustic features. Here are some nice plots on the evolution of number of pieces per year, and some of the most relevant acoustic features. We first observe that most of the pieces belong to the period from 1990’s to nowadays. This may be an artifact of the people who have submitted data to AcousticBrainz, and also of the data that we find in MusicBrainz. We hope that this distribution will spread out as we get more and more tracks.
Distribution of release year for the dataset. 0 represents an unknown year
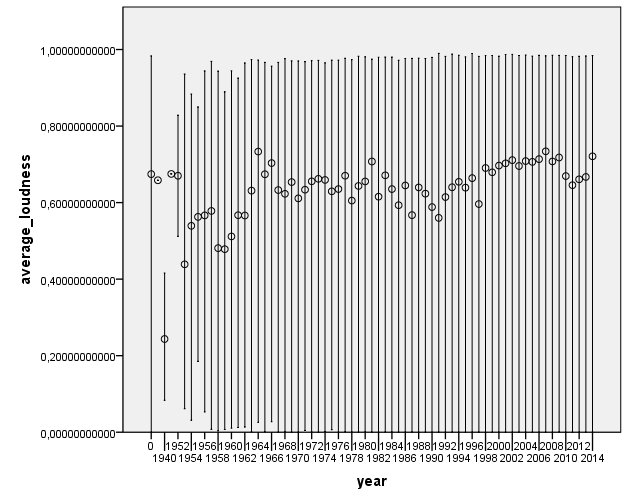
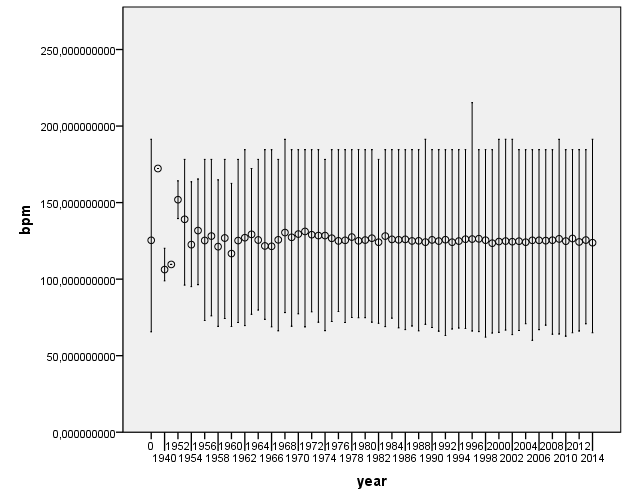
There does not seem to be a large change of acoustic features as year changes. This is definitely something to look into further to see if any of the changes are statistically significant.
Are the loudness wars true? Can you see a trend?
Is music getting faster? It doesn’t look like it
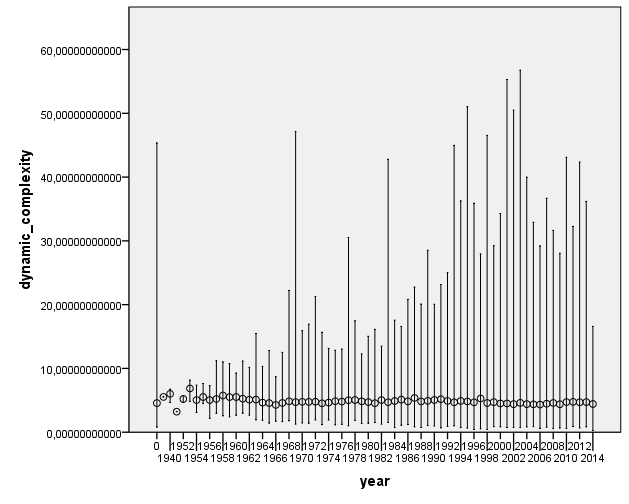
Songs aren’t geting more complex
We have many more ideas of ways to look at this data, and hope that it will show us some interesting things that we may not have guessed from just listening to it. If you would like to see any other statistics, please let us know! You can download the whole dataset to perform your own analysis at http://acousticbrainz.org/download
What is AcousticBrainz?
The AcousticBrainz project aims to crowd source acoustic information for all of the music in the world and make it available to the public. The goal of AcousticBrainz is to provide music technology researchers and open source hackers with a massive database of information about music.
AcousticBrainz uses a state of the art research project called Essentia (http://essentia.upf.edu/), developed over the last 10 years at the Music Technology Group.
Data generated from processing audio files with Essentia is collected by the AcousticBrainz project and made available to the public under the CC0 license (public domain). In 6 weeks since its inception, AcousticBrainz contributors have already submitted data for 650,000 audio tracks using pre-release software.
Today we are releasing client programs to submit data to the AcousticBrainz server and our first public release containing audio features for over 650,000 audio files.
What data does it have?
AcousticBrainz contains information called audio features. This acoustic information describes the acoustic characteristics of music and includes low-level spectral information such as tempo, and additional high level descriptors for genres, moods, keys, scales and much more. These features are explained in more detail at http://acousticbrainz.org/sample-data
What can I do with it?
We hope that this database will spur the development of new music technology research and allow music hackers to create new and interesting recommendation and music discovery engines. Here are some ideas of things we would like to see:
Music discovery
Playlist generation
Improving the state of the art in genre recognition
Analytics on the musical structure of popular music
and more!
This is one of the largest datasets of this kind available for research, and the only one of this size that we know of which contains both freely available data as well as the reference source code used to compute the data.
How can I contribute? If you are a music researcher, you can help us by contributing to the essentia project. Go to the essentia homepage to see how you can do this. If you do something cool with the data let us know. We’d like to start a “made with AcousticBrainz” page where we will showcase interesting projects.
If you have any audio files, we would love for you to contribute audio features to our project. You can do this by downloading our submission clients from http://acousticbrainz.org/download. We provide clients for Windows, Mac, and Linux.