
We’re pleased to announce that we have just released acoustic similarity in AcousticBrainz. Acoustic similarity is a technique to automatically identify which recordings sound similar to other recordings, using only the recordings themselves, and not any additional metadata. This feature is available via the AcousticBrainz API and the AcousticBrainz website, from any recording page. General documentation on acoustic similarity is available at https://acousticbrainz.readthedocs.io/similarity.html.
This feature is based on work started by Philip Tovstogan at the Music Technology Group, the research group that provides the essentia feature extractor that powers AcousticBrainz. The work was continued by Aidan Lawford-Wickham during Summer of Code 2019. Thanks Philip and Aidan for your work!
From the recording view on AcousticBrainz, you can choose to see similar recordings and choose which similarity metric you want to use. Then, a list of recordings similar to the initial recording will be shown.
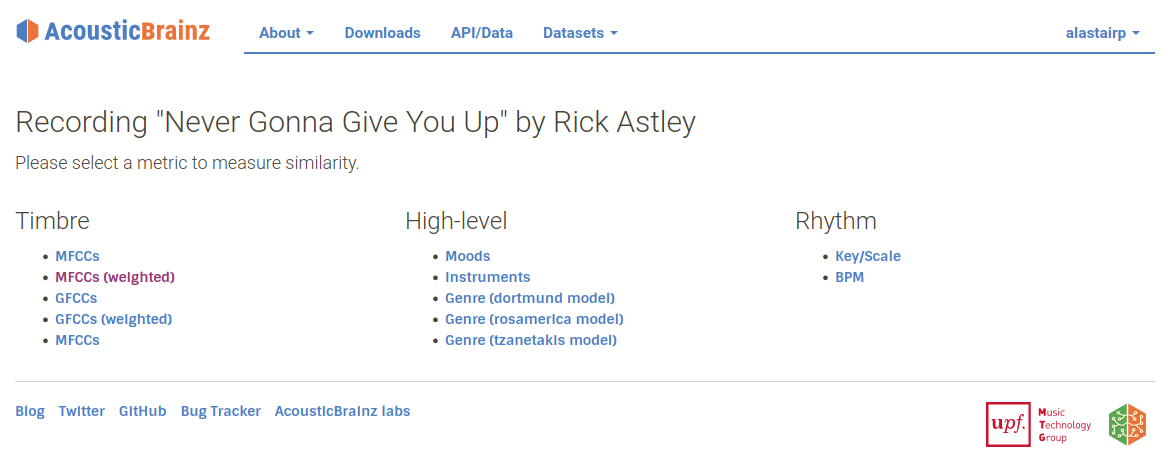
These metrics are based on different musical features that the AcousticBrainz feature extractor identifies in the audio file. Some of these features are related to timbral characteristics (generally, what something sounds like), Rhythmic (related to tempo or perceived pulses), or AcousticBrainz’s high-level features (hybrid features that use our machine learning system to identify features such as genre, mood, or instrumentation).
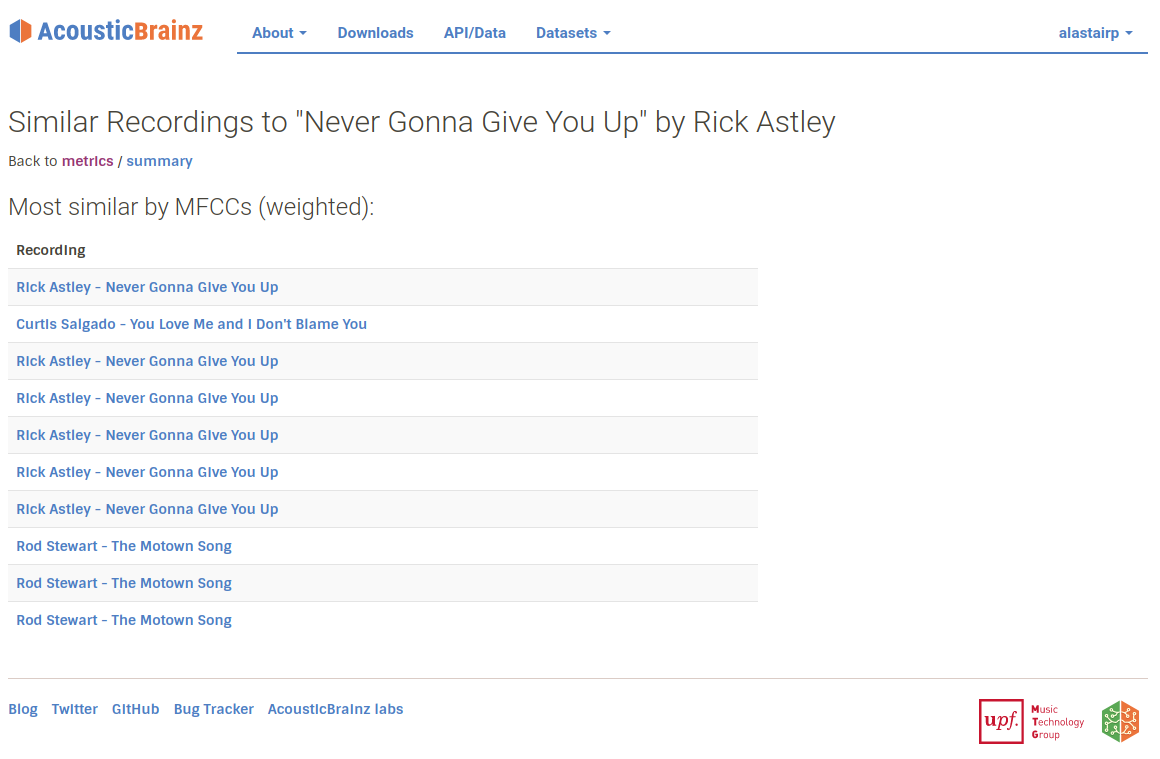
One thing that we can immediately see in these results is that the same recording appears many times. This is because AcousticBrainz stores multiple different submissions for the same MBID, and will sometimes get submissions for the same recording with different MBIDs if the data in MusicBrainz is like this. This is actually really interesting! It shows us that we are successfully identifying that two different submissions in AcousticBrainz as being the same using only acoustic information and no metadata. Using the API you can ask to remove these duplicated MBIDs from the results, and we have some future plans to use MusicBrainz metadata to filter more of these results when needed.
What’s next?
We haven’t yet performed a thorough evaluation of the quality of these similarity results. We’d like people to use them and give us feedback on what they think. In the future we may look at performing some user studies in order to see if some specific features tend to give results that people consider “more” similar than others. AcousticBrainz has a number of additional features in our database, and we’d like to experiment with these to see if they can be used as similarity metrics as well.
The fact that we can identify the same recording as being similar even when the MusicBrainz ID is different is interesting. It could be useful to use this similarity to identify when two recordings could be merged in MusicBrainz.
The data files used for this similarity are stand-alone, and can be used without additional data from AcousticBrainz or MusicBrainz. We’re looking at ways that we can make these data files downloadable so that developers can use them without having to query the AcousticBrainz API. If you think that you might be interested in this, let us know!
What are the main differences between your “metrics [are] based on different musical features that the AcousticBrainz feature extractor identifies in the audio file” and those on AcoustID.org?
This is a great question. Both AcoustiID and some of the similarity features in AcousticBrainz share very similar techniques. Chromaprint (the fingerprinting system used by AcoustID) uses a technique called Bark Bands to obtain a representation of the audio recording (https://en.wikipedia.org/wiki/Bark_scale). Crucially, it computes data approximately every 0.5 seconds of a song, and when comparing two recordings it looks at how this data is similar over the duration of the song. More information about how chromaprint works is available at https://oxygene.sk/2011/01/how-does-chromaprint-work/
The MFCCs similarity in AcousticBrainz uses a very similar technique (https://en.wikipedia.org/wiki/Mel-frequency_cepstrum). Both the Mel scale and the Bark scale are designed to convert frequency in a music recording to a representation that approximates how people perceive pitch.
The AcousticBrainz similarity technique is more general than chromaprint. Unlike chromaprint it doesn’t calculate a value as it changes over the duration of the song. Instead it has just 1 single “average” value. This makes it more useful for some tasks, but means that it’s not as accurate if you wish to very specifically identify if 2 recordings are exactly the same. Because in AcousticBrainz we compute more features than just the chroma similarity (i.e. we also compute rhythmic features, tonal/key features, and features powered by our machine learning system) we are able to show different types of similarity (songs that use a similar instrumentation, songs that are more or less in the same genere, songs that are about the same speed). As I mentioned in the last section we hope to soon perform some evaluation of the different features that we have available to see which ones are useful for people.
@Invisibleman The approach AcoustID uses is very crude. AcoustID doesn’t care about the musical content at all. It just wants to extract some arbitrary data that is useful for identifying the song and identifying it really efficiently.
The approach from AcoustidBrainz has the capacity to actually have some musical value. With all the data it’s collecting, it can be making decisions based on the musical content, not just by arbitrary hashes. It could be used to identify musical concepts. While I’m not all that familiar with the most recent AcoustidBrainz data, there is much much more that can be done with this. On the other hand, AcoustID is a one-trick pony. 🙂
Are the two AcousticBrainz similarity endpoints still working? I want to use them for a school project. I saw somewhere that AcousticBrainz had shut down
Hi Frankie, the AcousticBrainz project has been ended two years ago. The API is still available in read-only mode. See the final blog post for details.