
Month: March 2015
Server update, 2015-03-23
Today’s release focuses on fixing various editing bugs, particularly in the release editor. For those who use the track parser often, it should be a lot better at retaining track MBIDs after you reuse recordings now.
The entire list of changes for today is below. Thanks to chirlu and the MetaBrainz team for working on these tickets.
The git tag is v-2015-03-23.
Bug
- [MBS-5108] – Setting end-date is no longer auto-edit
- [MBS-7719] – “Reuse previous recordings” button not available after using the track parser
- [MBS-7983] – After adding “translator” relationship, “translated” flag gets stuck for subsequent relationship
- [MBS-8212] – “Copy the release artist credit to the release group” on the release page is broken
- [MBS-8272] – Web service doesn’t output language or script for releases that are relationship targets
- [MBS-8285] – Unable to edit release with deprecated external links
- [MBS-8286] – Seeding URLs on Add Release is broken
- [MBS-8296] – It’s now impossible to re-order Release Groups in a Manual Series
Improvement
Spring schema change release: 18 May, 2015 & important Live Data Feed change
I’m pleased to announce our upcoming schema change release on 18 May, 2015. In this release we will implement each of the tickets listed in this fix version:
- MBS-1347: Implement aliases for release groups, releases and recordings.
- MBS-4145: Up/down vote for tags — This feature will be our first attempt at getting into “genres”. People have expressed that our tags are vaguely useful for genres, but expressed frustration at not being able to give feedback about the tags. Voting on tags will allow us to find the tags that people find useful, which will allow us to develop a list of tags that we consider to be “genres”.
- MBS-7489: Artist Credits for Relationships — This feature will allow MusicBrainz to store an alternate artist display name (Artist Credit) for a given credit (Advanced Relationship).
- MBS-8266: Make medium titles VARCHAR NOT NULL — Fixes a database inconsistency that should have little to no impact on end users.
- MBS-8279: Remove empty_artists etc. database functions — Another database/code refactoring that should also have little impact on end users.
- MBS-8283: Remove DB constraint that disallows empty event names — This allows event names to be blank, since many events do not have a proper name.
- MBS-8287: Log deleted entities that were in a subscribed collection — This feature will give users a notification if one of their subscribed entities is deleted.
- MBS-8302: Add Live Data Feed access token support — Add support for using access tokens. See below for more details.
UPDATE: We forgot to list the following change, which is already almost ready to go – apologies for the slightly late addition!
UPDATE 2: This change will not affect users of our replicated data at all, since the changes are to non-replicated tables. This is the only reason we decided to sneak this change in after the official announcement.
- MBS-8004: Extend collections to other entities — This extends the current ability to create collections (user-made lists) to other entities apart from releases and events. That means users can make arbitrary lists (“Artists I’ve seen live”, or “Songs I can play on the piano”), and also subscribe to them to get notified when anything on the collection is being edited.
Finally, I’m not describing MBS-8278, since that is an internal housekeeping reminder and will not really affect downstream users. All in all this is fairly light schema change for us, since we currently have a number of other projects that we wish to undertake in the medium term.
Important Live Data Feed change: After 10+ years of our Live Data Feed being available to anyone on the honor system, we are going to require Live Data Feed users to have an access token to fetch the replication packets for the Live Data Feed.
At the beginning of May we are going to release a new MetaBrainz web-site that will allow all of our current Live Data Feed users to create an account and to generate themselves an access token. Non-commercial users and existing commercial users will be immediately approved and will receive an access token. This access token will need to be add to your MusicBrainz-server (or mbslave) configuration in order for the Live Data Feed to continue to work as expected. Any new commercial users will need to sign up to one of the support tiers that the new web-site will present.
NB: If you are currently using the Live Data Feed legitimately, you should see no disruption to your use of the feed.
Postgres troubles resolved
I am glad to report that our problems are fixed and that our server is back to humming along nicely. The following is posted here so that if some other souls find themselves in our situation that they may learn form our experience:
What we changed:
- It was pointed out that max_connections of 500 was in fact insanely high, especially in light of using PGbouncer. Before we used PGbouncer we needed a lot more connections and when we started using PGbouncer, we never reduced this number.
- Our server_lifetime was set far too high (1 hour). Josh Berkus suggested lowering that to 5 minutes.
- We reduced the number of PGbouncer active connections to the DB.
What we learned:
- We had too many backends
- The backends were being kept around for too long by PGbouncer.
- This caused too many idle backends to kick around. Once we exhausted physical ram, we started swapping.
- Linux 3.2 apparently has some less than desirable swap behaviours. Once we started swapping, everything went nuts.
Going forward we’re going to upgrade our kernel the next time we have down time for our site and the rest should be sorted now.
Finally a word about Postgres itself:
Postgres rocks our world. I’m immensely pleased that once again the problems were our own stupidity and not Postgres’ fault. In over 10 years of using Postgres, problems with our site have never been Postgres’ fault. Not once.
Thanks to everyone who helped us through this tough time!
Postgres troubles
(Regular readers of this blog, please ignore this post. We’re casting a wide net to try and find help for our problems.)
UPDATE: This problem has been resolved and all of our services are returning to their normally dubious service levels. For a technical explanation of what went wrong, see here.
Dear Postgres gurus:
We at MusicBrainz have been very happy postgres users for over a decade now and Postgres is something that gives is very few headaches compared to all the other things that we run. But last week we started having some really vexing issues with our server. Here is some back-story:
http://blog.musicbrainz.org/2015/03/14/hosting-issues-downtime-tonight/
When our load spiked, we did the normal set of things that you do:
- Check for missing indexes, made some new ones, no change. (see details below)
- Examined for new traffic; none of our web front end servers showed an increase in traffic.
- Eliminated non-mission-critical uses of the DB server: stop building indexes for search, turn off lower priority sites. No change.
- Review the performance settings of the server. Debate each setting as a team and tune. shared_buffers and work_mem tuning has made the server more resilient to recover from spikes, but still, we get massive periodic spikes.
From a restart, everything is happy and working well. Postgres will use all available ram for a while, but stay out of swap, exactly what we want it to do. But then, it tips the scales and digs into swap and everything goes to hell. We’ve studied this post for quite some time and ran queries to understand how Posgres manages its ram:
http://www.depesz.com/2012/06/09/how-much-ram-is-postgresql-using/
And sure enough ram usage just keeps increasing and once we go beyond physical ram, it goes into swap. Not rocket science. We’ve noticed that our back ends keep growing in size. According to top, once we start having processes that are 10+% of ram, we’re nearly on the cusp of entering swap. It happens predictably time and time again. Selective use of pg_terminate_backend() of these large back ends can keep us out of swap. A new, smaller backend gets created, RAM usage goes down. However, this is hardly a viable solution.
We’re now on Postgres 9.1.15, and we have a lot of downstream users who also need to upgrade when we do, so this is something that we need to coordinate months in advance. Going to 9.4 is out in the short term. 🙁 Ideally we can figure out what might be going wrong so we can fix it post-haste. MusicBrainz has been barely usable for the past few days. 🙁
One final thought: We have an several tables from a previous version of the DB sitting in the public schema not being used at all. We keep meaning to drop those tables, but haven’t gotten around to it yet. They tables are not being used at all, so we assume that they should not impact the performance of Postgres. Might this be a problem?
So, any tips or words of advice you have for us, would be deeply appreciated. And now for way too much information about our setup:
Postgres:
9.1.15 (from ubuntu packages)
Host:
- Linux totoro 3.2.0-57-generic #87-Ubuntu SMP Tue Nov 12 21:35:10 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
- 48GB ram
- Raid 1,0 disks
- PgBouncer in use.
- Running postgres is its only task
postgresql.conf:
archive_command = '/bin/true' archive_mode = 'on' autovacuum = 'on' checkpoint_segments = '128' datestyle = 'iso, mdy' default_statistics_target = '300' default_text_search_config = 'pg_catalog.english' data_directory = '/home/postgres/postgres9' effective_cache_size = '30GB' hot_standby = 'on' lc_messages = 'en_US.UTF-8' lc_monetary = 'en_US.UTF-8' lc_numeric = 'en_US.UTF-8' lc_time = 'en_US.UTF-8' listen_addresses = '*' log_destination = 'syslog' log_line_prefix = '<%r %a %p>' log_lock_waits = 'on' log_min_duration_statement = '1000' maintenance_work_mem = '64MB' max_connections = '500' max_prepared_transactions = '25' max_wal_senders = '3' custom_variable_classes = 'pg_stat_statements' pg_stat_statements.max = '1000' pg_stat_statements.save = 'off' pg_stat_statements.track = 'top' pg_stat_statements.track_utility = 'off' shared_preload_libraries = 'pg_stat_statements,pg_amqp' shared_buffers = '12GB' silent_mode = 'on' temp_buffers = '8MB' track_activities = 'on' track_counts = 'on' wal_buffers = '16MB' wal_keep_segments = '128' wal_level = 'hot_standby' wal_sync_method = 'fdatasync' work_mem = '64MB'
pgbouncer.ini:
[databases] musicbrainz_db_20110516 = host=127.0.0.1 dbname=musicbrainz_db_20110516 [pgbouncer] pidfile=/home/postgres/postgres9/pgbouncer.pid listen_addr=* listen_port=6899 user=postgres auth_file=/etc/pgbouncer/userlist.txt auth_type=trust pool_mode=session min_pool_size=10 default_pool_size=320 reserve_pool_size=10 reserve_pool_timeout=1.0 idle_transaction_timeout=0 max_client_conn=400 log_connections=0 log_disconnections=0 stats_period=3600 stats_users=postgres admin_users=musicbrainz_user
Monitoring:
To see these, enter these anti-spam passwords: User: “musicbrainz” passwd: “musicbrainz”
Indexes:
We ran the query from this suggestion to identify possible missing indexes:
http://stackoverflow.com/questions/3318727/postgresql-index-usage-analysis
this is our result:
https://gist.github.com/mayhem/423b084043235fb78642
Most of these tables are tiny and kept in ram. Postgres opts to not use any indexes we create on the DB, so no change.
UPDATES:
- Five months ago we double the RAM from 24GB to 48GB, but our traffic has not increased.
- We’ve set kernel.swapiness to 0 with no real change.
- free -m:
total used free shared buffers cached Mem: 48295 31673 16622 0 5 12670 -/+ buffers/cache: 18997 29298 Swap: 22852 2382 20470
Hosting issues & downtime tonight
For the past week we’ve been battling a variety of hosting issues from search servers acting up, gateways dropping packets and now our database server freaking out for no particular reason. We managed to fix/mitigate the issues in the first hiccups, which is good. And for three days everything looked peachy. Then, out of the blue our database server did this:
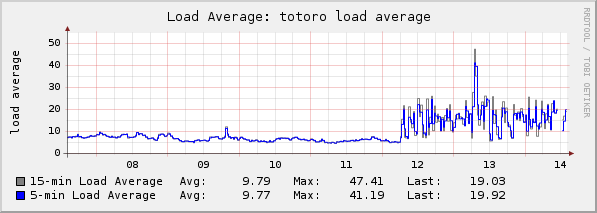
You don’t have to understand much about hosting computers to understand that this is bad. Out of the blue our server started having to work much harder than before. Normally that means that something using the server has changed. We’ve looked for a traffic increase — we can’t find one. We’ve examine someone being abusive to us — we found a couple users, but blocking them didn’t change anything. We tried turning off non-essential services that make use of the database server, but nothing ever changes. We’ve restarted the database server. We’ve slapped this, we’ve poked that, we’ve prodded, undid and tested just about everything we can think of. But, the load comes in spikes and recedes again; over and over.
We’ve had amazing help from a number of people, but several skilled computer geeks with a support from lots of others haven’t managed to make a dent in things. We’re exhausted and we need a bit of a break. So, that’s what we’re doing for the next 7 or so hours.
Then at 15h PDT, 18h EDT, 22h UK, 23h CET we’re going to start to upgrade to the latest version of Postgres 9.1. We hope to be down for less than half an hour — but you never know. We’ll tweet about the downtime and put up a banner on the MusicBrainz site to let people know when exactly we’ll take the site down.
Sorry for the hassle — we’re all amazingly frustrated right now — please bear with us.
Server update, 2015-03-09
This one’s mostly a small bug-fix release, since improvements to sitemaps and other big projects have been concurrently in the works. One thing of note is that the “external links editor” on entity edit pages was rewritten to be more maintainable in the long run; hopefully no bugs have creeped in with the new code, but if any have then please report them on our issue tracker!
Thanks to reosarevok and the MetaBrainz team for working on the changes below. The git tag is v-2015-03-09.
Bug
- [MBS-8055] – Series-Series relationships are blocked by JS
- [MBS-8151] – Filename not being shown in remove cover art edits
- [MBS-8221] – Work pages don’t show event rels
- [MBS-8270] – Bottom display of work relationships is inaccurate for works appearing across multiple tracks
Improvement
Branding brief
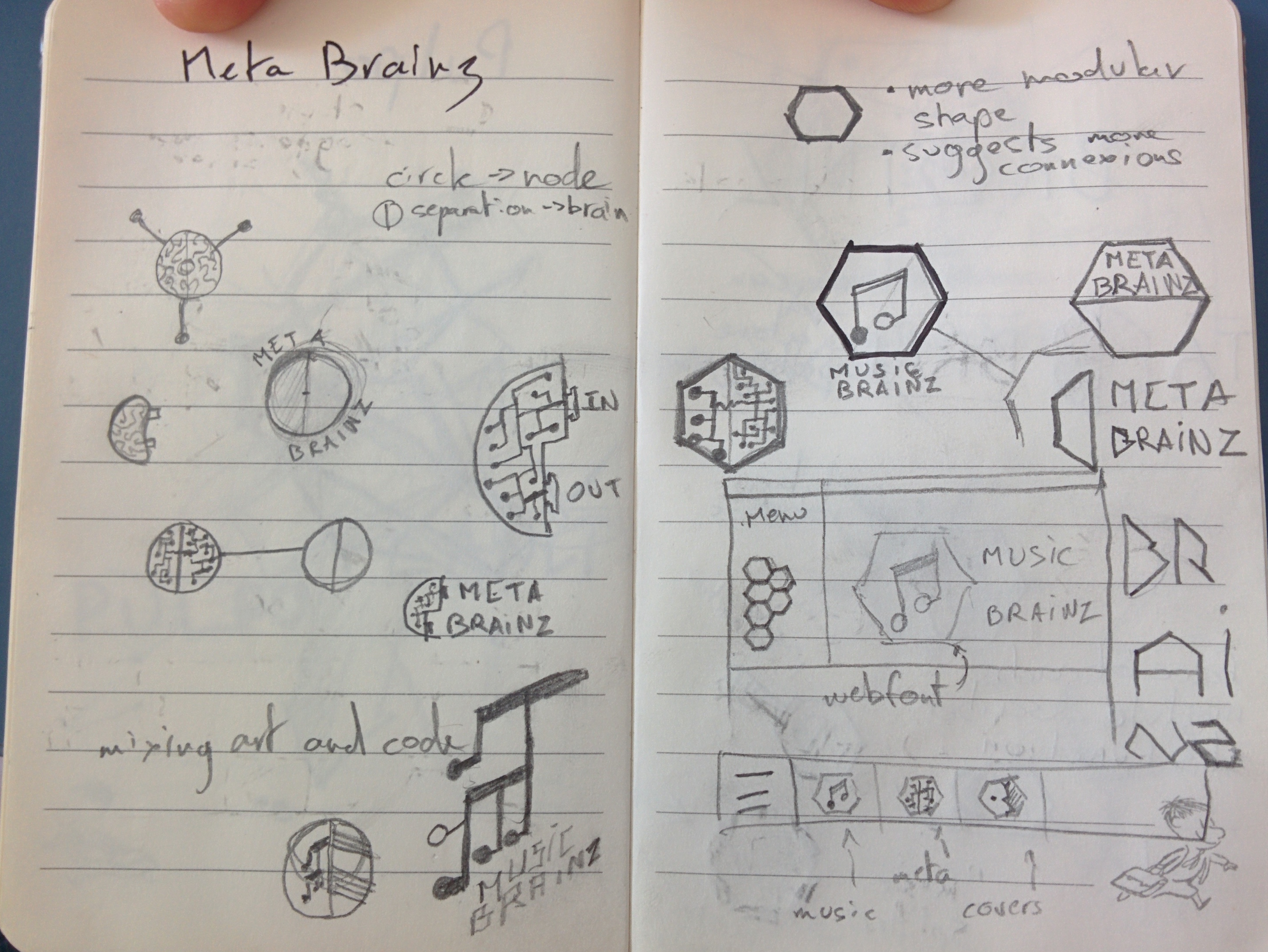
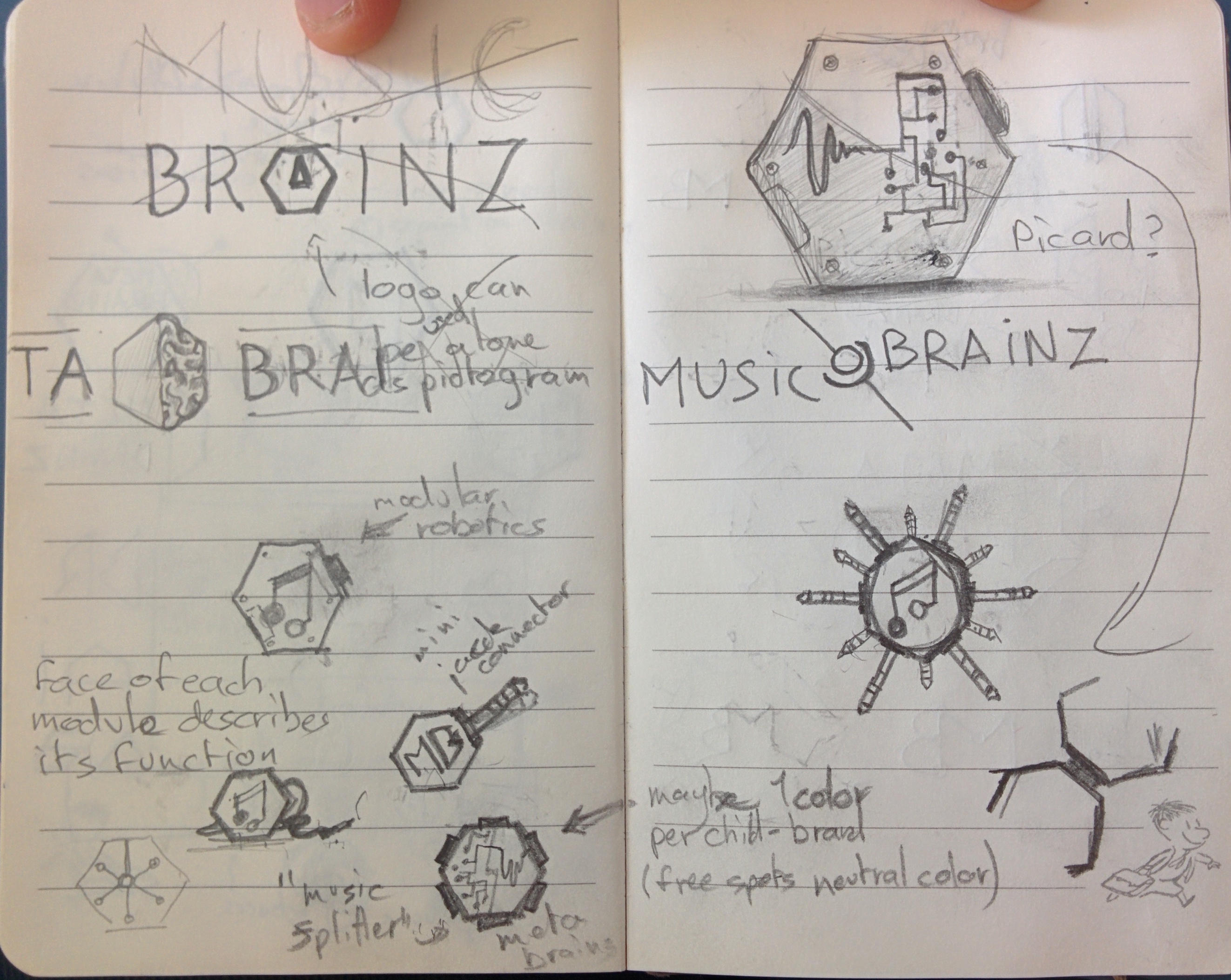
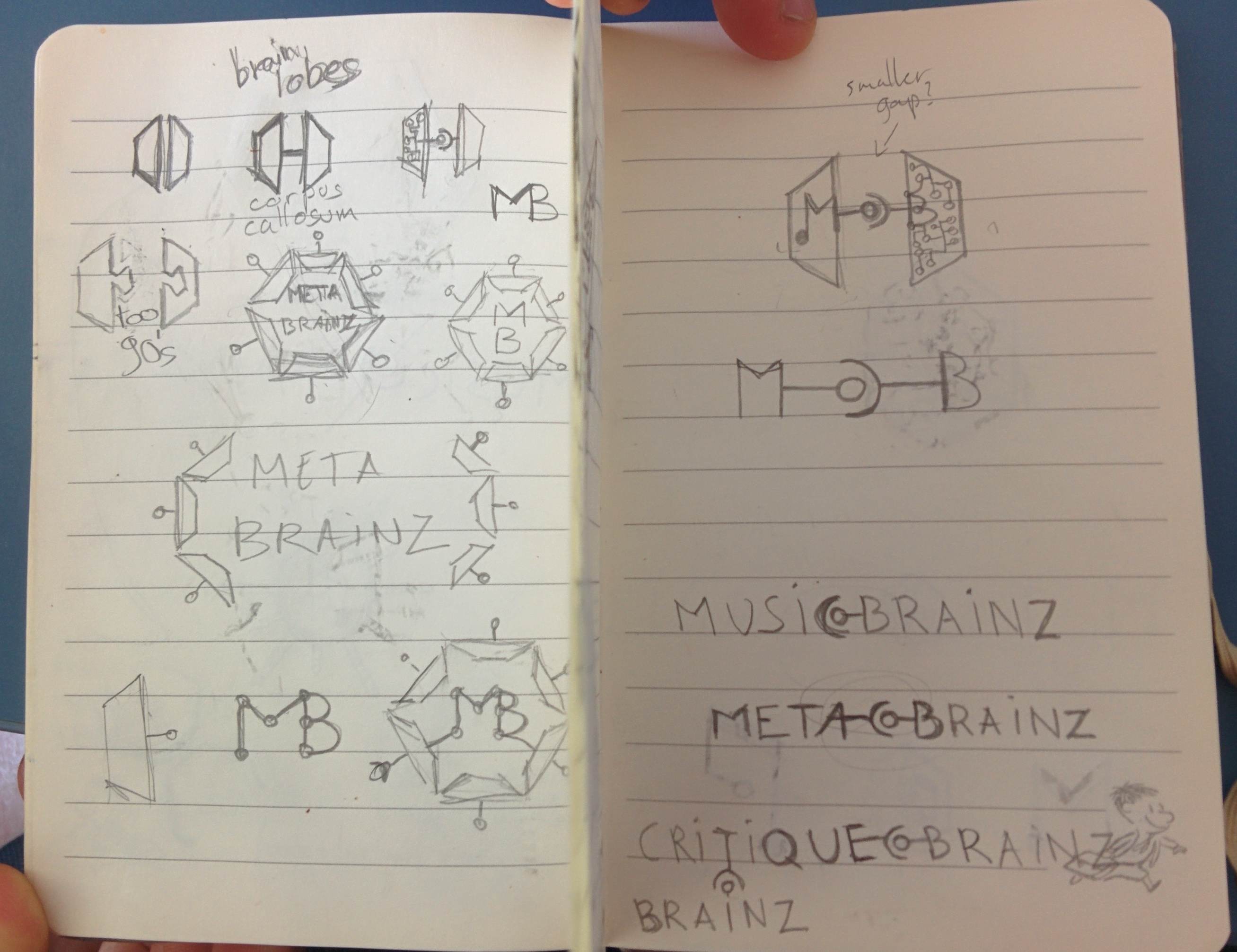
My friend Niclas Ljungberg overheard me complain about how discombobulated and disconnected the MetaBrainz branding currently is. There is some cohesion between MusicBrainz and MetaBrainz, but almost none to the newer projects like CritiqueBrainz and AcousticBrainz. And very few people are fond of the current logos (plus, they haven’t aged very well). When Niclas heard this, he said: “I can help you!”.
Getting help in the area of marketing and business is rare, so I jumped at the chance. Niclas and I sat down where Niclas interviewed me about how all the pieces currently fit together and how I think they should fit together. The deliverable from this conversation is a “Branding brief” (PDF). It talks about the current state of things, the goals and then gives context and some suggestions that a graphic designer can use to start designing cohesive logos and cohesive site designs that we can use for our sites. It does not propose any concrete actions — please keep that in mind when you read the brief.
The next step is to work with a designer to turn Niclas’ branding brief into some logo concepts that meet the outlined goals. At this point, we’re not exactly ready to take any concrete feedback from the community — I’m mostly sharing this to show that I’ve started a process to fix our current branding situation.
I’m very happy with how far things have come in this process and I wanted to give a heartfelt thanks to Nicals for donating his time to help us improve our overall presence on the net.
Thank you Niclas!
We’ve been accepted to Summer of Code!
I’m pleased to announce that we’ve been accepted to Google’s Summer of Code program for 2015!
If you’re an qualifying student who is interested in working on MusicBrainz or its related projects, check out our ideas page! If you are new to the MusicBrainz community (welcome!), we have also made a “getting started” page to get you going.