
The 2019 MetaBrainz Summit took place on 27th–29th of September 2019 in Barcelona, Spain at the MetaBrainz HQ. The Summit is a chance for MetaBrainz staff and the community to gather and plan ahead for the next year. This report is a recap of what was discussed and what lies ahead for the community.
What is a Summit?
The Summits are a once-annual gathering of MetaBrainz staff and contributors working on key project areas. This year, the Summit was attended by the following folks:
- Aidan Lawford-Wickham (aidanlw17)
- Alastair
- Anirudh Jain (Cyna)
- Frederik “Freso” Sandberg Olesen
- Justin W. Flory (jwf/jflory)
- Michael Wiencek (bitmap)
- Monkey
- Nicolás (reosarevok)
- ruaok
- Vansika Pareek
- YvanZo
- Zas
The Summit took place at the MetaBrainz HQ in Barcelona, Spain. Over the course of one weekend, the team and community took on an ambitious agenda of tasks and discussions:
- Genres
- Memory caching
- Edit system moderation / revamp
- Spam + sock puppets
- Solr
- Google Code-In
- Postgres 10
- API design (v2.5)
- Community engagement
- Momentum in our projects
- Future hack days
- ListenBrainz Labs
- How to implement user scripts (e.g. classical music)
This blog post won’t summarize all the discussion above, but it will try to emphasize some of the more interesting discussions. (For the full details, peek at the Summit 2019 notes document or the archived live stream.)
Community updates
The Summit began with a quick recap from all different project teams. The notes from the Summit are included below based on the project and who presented on it. Click to navigate to what you want to stay informed on:
- Rob: MetaBrainz update
- Bitmap: MusicBrainz development update
- Freso: Community update
- Monkey: BookBrainz update
- Alastair: AcousticBrainz update
- Zas: Infrastructure update
- Vansika: ListenBrainz Labs
- Aidan: AcousticBrainz GSoC summary
- Cyna: MusicBrainz edit previews – GSoC update
Where *Brainz is going
Engineering
Engineering efforts can be divided into two sub-categories: Code and Infrastructure.
Code
Future steps for code are focused around genres, user script engagement, API key design, and an editing system overhaul.
Genres are an eternal topic across the MetaBrainz Summits, but now, they finally exist and are implemented in the front-end and back-end. There was some talk about whether MusicBrainz should be deciding what is or is not a genre; some UPF MTG datasets (ISMIR2004 Genre dataset, MediaEval AcousticBrainz Genre) were mentioned, which collect genres and map them in some way to MBIDs. Aliases for genres are also planned, but there are still some edge cases to consider, like whether an alias could apply to two genres.
User script engagement comes from MetaBrainz wanting a better integration of MusicBrainz with popular user scripts. The team recognized the usefulness of user scripts to create popular tweaks and changes to the viewing or editing experience of MusicBrainz data. Not only do they help other users, but it also gives the development team feedback of popular features to add into MusicBrainz properly. The concerns highlighted here were around scripts that perform mass edits across multiple releases; with great power, comes greater responsibility if implementing something like this in the database. The team did not come to a closing resolution on how to make this a better collaboration. If you are a member of the user script community, we’d love to hear your thoughts on this in Discourse.
API key design comes from MetaBrainz wishing to have greater understanding who uses our data and how, particularly around the Live Data Feed. The intended approach is to use mandatory API keys for end-users to authenticate with. Part of this is an authentication system question (considering an OAuth2 migration) and how to handle dates and times in the API. Monkey was actioned to formalize a proposal at a later date for moving this conversation forward.
An editing system overhaul was one of the most ambitious discussions held at the Summit. The need for an overhaul comes from challenges around scaling and growing the database. It also comes from a discussion about isolating the editing system of MusicBrainz from the actual project; for example, this could enable BookBrainz to use the same editor “code” as MusicBrainz, while allowing each to take a different form for their types of data. A git‐like editing system was proposed and some early architecture research was completed by the end of the Summit.
Infrastructure
Future steps and projects for infrastructure were around Docker/container orchestration and indexed search.
There are two components to how MetaBrainz uses Docker and containers: for local development and production deployment. Local development helps developers run a project on their own hardware and test their changes. Production deployment concerns how containers are deployed in an infrastructure environment. The infrastructure team hopes to standardize on Docker best practices for development. More consistency across projects helps existing contributors jump into new areas or other projects more easily. Another part of this conversation was around container orchestration with Kubernetes or OpenShift, but more research is needed to understand the cost-value of doing this work. There is limited bandwidth for the infrastructure team to take on new projects and meet current demands.
YvanZo started the conversation on indexed search by reviewing the Solr set-up documentation. The discussion moved to the Search Index Rebuilder (SIR) and pending work to improve performance and resource load. More notes from the discussion are available.
Community
The community updates were divided into three pieces: community engagement, documentation roadmap, and Google Code-In.
Community engagement
The community engagement discussion started with a map of the MetaBrainz community by Justin W. Flory:
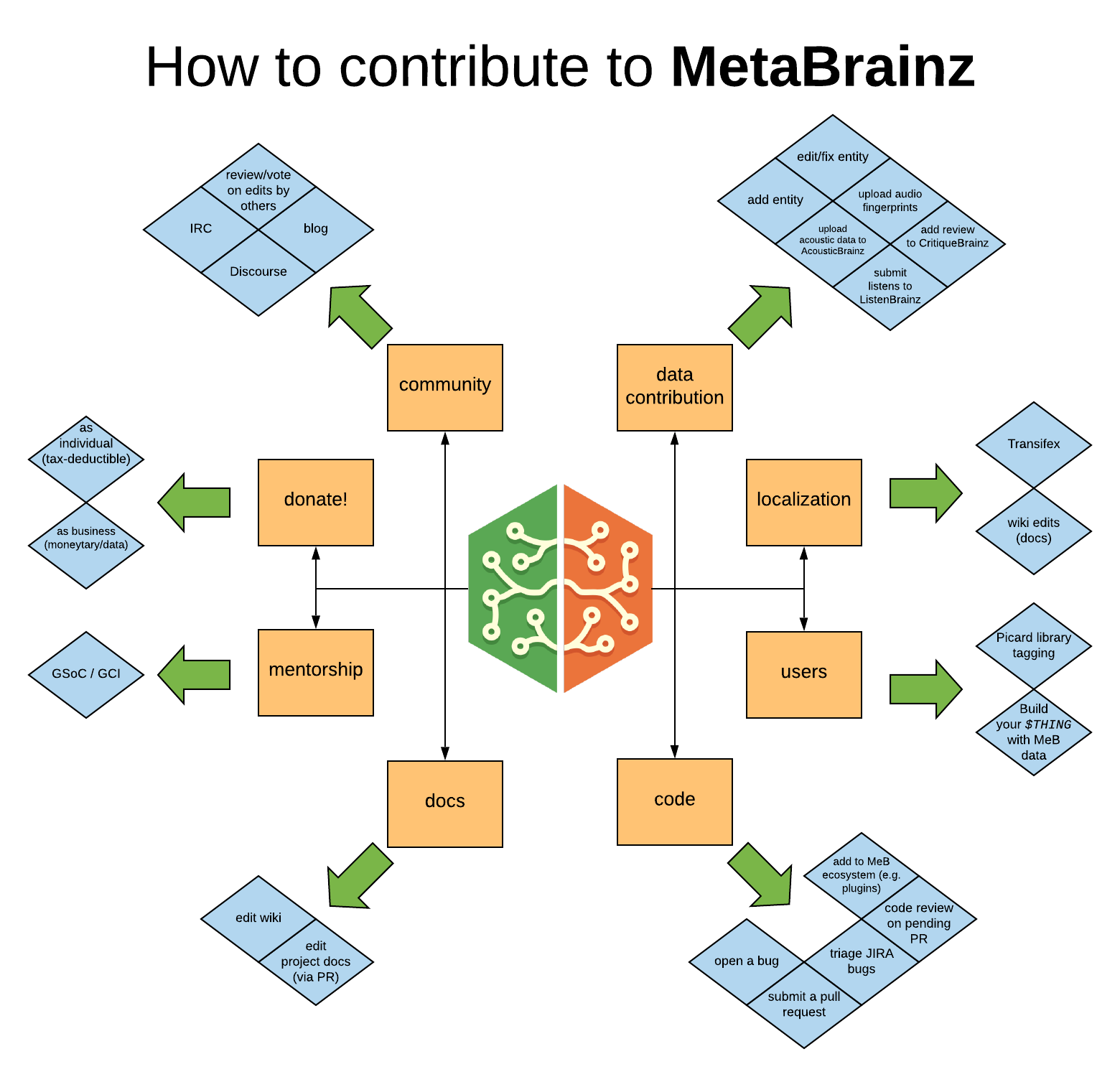
Three different initiatives were suggested as ways to enable existing and new contributors in a variety of ways, not all code-related:
- Community index
- Chat bridges
- Advocacy program
The community index is a “point of entry” for anyone who wants to get involved with a MetaBrainz project. The flowchart above describes the different ways to get involved, but there is not a good pathway for someone to get directed to the best way they can help. An example of what we want to create is similar to whatcanidoformozilla.org or whatcanidoforfedora.org. This is still a discussion in progress, but if you are interested, please vote and/or comment on JIRA ticket ORG-36.
The MetaBrainz community is deeply rooted in IRC, but IRC is not an easy-to-use tool for everyone. Some folks use IRCCloud as a way to get around this, but for new contributors, IRC is not an accessible platform. One way to get around this is with chat bridges. At the Summit, we committed to exploring a chat bridge, possibly between our IRC channels and Telegram groups. An IRC channel would be linked to a Telegram group, so messages in one appear in the other. This is one social experiment we want to try for bringing new people into the MetaBrainz community. Future progress is waiting on an upstream feature request to be implemented.
An advocacy program aims to empower the community to present MetaBrainz projects, and their own works linked to MetaBrainz, at various events around the world. This follows models set by other larger community projects that implement a community ambassador or advocacy program. More discussion is needed, but if you are interested in this, please vote and/or comment on JIRA ticket ORG-24.
Documentation roadmap
How do we make our documentation more useful and practical? See this spin-off discussion in the forums for more information. To keep up with future changes, please vote and/or comment on JIRA ticket OTHER-350.
Google Code-In
Google Code-in was led by Freso. We quickly jumped to discussions of how to start planning for participation this year. Fortunately, we are able to use last year’s tasks as a base for writing new tasks this year. We still need help with mentorship and planning, so if you want to get involved with that, please reach out via the usual channels.
Thanks!
This event would not have been possible without the support of Microsoft. Thank you for supporting the engagements and interactions that support this project in the best possible way.
Thanks everyone who travelled from near and far (and those who couldn’t be there together with us), brought lots of yummy chocolates, danced Bollywood style during breaks, and helped contribute towards a more Free world of music and technology.