Picard 1.3.2 is now available on the Picard download page. This again is only a small maintenance release which mainly updates the OS X build to fix crashes some users experienced with Picard 1.3.1. Here is the complete list of fixes:
Bug
[PICARD-681] Fixed tags from filename dialog not opening on new installations
This release is quite small because it overlapped with the holidays, but contains a fix for an annoying guess-case issue in the release editor that several people reported. Thanks to chirlu for the rest of the bug fixes listed here!
The git tag is v-2014-12-29.
Bug
[MBS-4668] – Edit search loses selections when the page number is too high
[MBS-8064] – Can’t add documentation to migration-created relationship types
[MBS-8086] – Guess case for release title does not trigger an edit
[MBS-8091] – Can’t fix non-normalized artist credits
We’ve released another server update today, though a fairly modest one, since bigger changes have been happening in the background with embedding JSON-LD into our pages and switching our JavaScript over to browserify. A few more edit types have been made auto-edits for everyone, as detailed in the changelog below. There’s additionally been some misc. UI changes, and a fix to output artist genders in the JSON webservice.
Thanks to chirlu, nikki, reosarevok, and the MetaBrainz team for their hard work on today’s release.
The git tag is v-2014-12-15.
Bug
[MBS-7916] – “Set track durations” preview is broken for single-track mediums
[MBS-8008] – “Add Event” (entity) and “Add Event” (release event) share the same translation string
[MBS-8044] – Map doesn’t zoom when pasting coordinates
[MBS-8066] – “Date” field wraps inconsistently in different browsers
[MBS-8082] – Gender missing on artist lookup (JSON)
Improvement
[MBS-7478] – Make more use of HTML5 form field types
[MBS-7970] – Replace guess case bubbles with icons next to the fields
[MBS-7973] – Make remove alias/ISRC/ISWC edits auto-edits for auto-editors
This Friday we’re going to need to take a 15-20 minute downtime to fix a few leftover issues from our recent schema change. We tried to do this without downtime, but the service got progressively slower, so we’re electing to take some downtime.
After skipping a fortnight because of concentrating on the schema change release, here’s the next edition of the style update, with all the changes from the last month. Most of the changes involve adding new medium formats and new place/area relationships, plus making changes and additions related to the new schema change features (events and data tracks).
The biggest change this month is the addition of a classical music titles guideline. This deprecates the old Opera Tracks guideline, and basically just provides a certain amount of standardisation while keeping mostly true to the on-cover titles.
A day late, but hopefully no dollars short, we’re back with another release. This release is mostly bug fixes, as you’d expect right after a schema change release. nikki has done some work with our CSS, however, and chirlu did some work updating and clarifying our INSTALL.md. Thanks to them, mineo, and the MetaBrainz team for their work this release!
The git tag for this release is v-2014-12-01.
The usual list of bugs fixed:
Bug
[MBS-4232] – Edit artist shows artists credits section when it doesn’t apply
[MBS-4622] – Improve handling of cover art when JS is off
[MBS-6971] – No controls for uploading cover artwork in IE8
[MBS-7497] – cpanm install fails with Can’t locate File/Copy/Recursive.pm in @INC
[MBS-7952] – Release editor does not handle removed mediums correctly when reordering mediums
[MBS-7988] – Adding a pregap track to an existing tracklist and it shows as a data track
[MBS-7992] – Data track option doesn’t behave properly with disc IDs
[MBS-7993] – Edit medium edits for pre-gap tracks claim to change data tracks
[MBS-7995] – DBDefs.pm.sample is still at schema version 20
This upgrade shouldn’t be substantially different than past upgrades, now that we’ve fixed a few bugs with the process. To upgrade:
Make sure your REPLICATION_TYPE setting is RT_SLAVE and your DB_SCHEMA_SEQUENCE is set to 20 in lib/DBDefs.pm.
Ensure you’ve replicated up to the most recent replication packet available with the old schema. (if you’re not sure, run ./admin/replication/LoadReplicationChanges and see what it tells you).
Take down the web server running MusicBrainz, if you’re running a web server.
Turn off cron jobs if you are automatically updating the database via cron jobs.
Switch to the new code with git fetch origin followed by git checkout schema-change-20-to-21
Run ./upgrade.sh (or carton exec -Ilib -- ./upgrade.sh if you’re using carton, with very old setups).
Set DB_SCHEMA_SEQUENCE to 21 in lib/DBDefs.pm
Turn cron jobs back on, if needed.
Restart the MusicBrainz web server, if applicable. It’s also recommended you restart memcached.
That’s it! The only real difference from the past is the specific tag to be used: schema-change-20-to-21, which is a couple of fix-up commits past the regular release tag.
Hot on the heels of our release of the first 650,000 feature files as part of the first release of AcousticBrainz, we are presenting some initial findings based on this dataset.
We thank Emilia Gómez (@emiliagogu), an Associate Professor and Senior Researcher at the Music Technology Group at Universitat Pompeu Fabra for doing this analysis and sharing her results with us. All of these results are based on data automatically computed by our Essentia audio analysis system. Nothing was decided by people. Isn’t that cool?
The MTG recently started the AcousticBrainz http://acousticbrainz.org/ project, in collaboration with MusicBrainz. Data collection started on September 10th, 2014, and since then a total of 656,471 tracks (488,658 unique ones) have been described with essentia. I have been working for a while with audio descriptors and I followed the porting some of my algorithms to essentia, especially chroma features and key estimation. For that reason, I was curious to get a look this data. I present here some basic statistics. I computed them with the SPSS statistical software.
WHICH KIND OF MUSICAL GENRES DO WE HAVE IN THE COLLECTION?
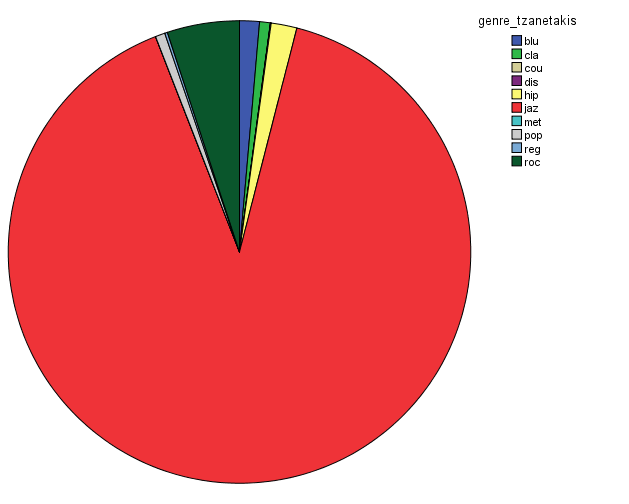
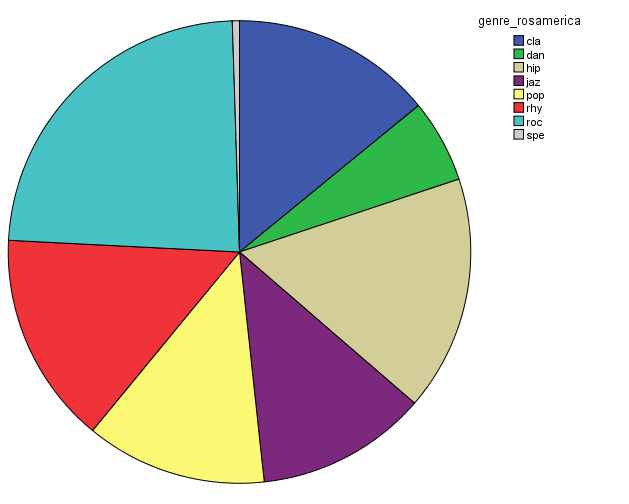
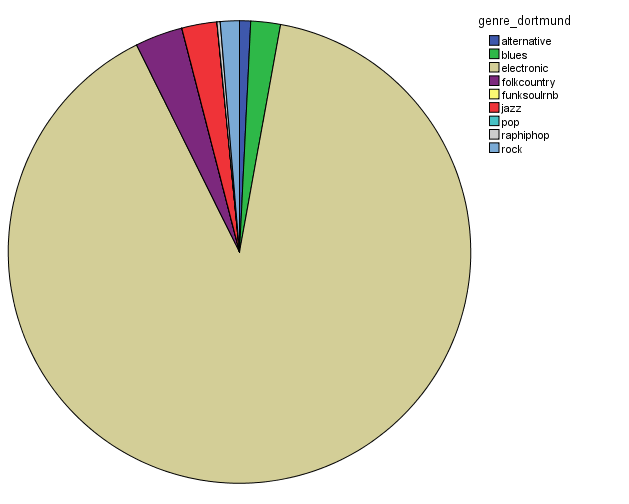
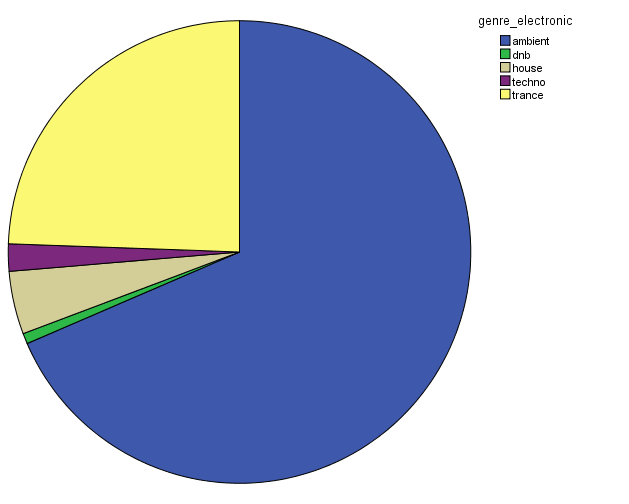
In order to characterize this dataset, I first thought about genre. In essentia, there are four different genre models: trained on the data by Tzanetakis (2001), another one compiled at the MTG (Rosamerica), Dortmund and a database of Electronic music. Far from providing information on the kind of musical genres, these models seem to be contradictory! For example, in the Tzanetakis dataset “jazz” seems to be the most estimated genre, while the proportion of jazz excerpts is very small in the other models.
Genre estimations using the Tzanetakis datasetGenre estimations using the Rosamerica datasetGenre estimations using the Dortmund datasetGenre estimations using the Electronic dataset
So in conclusion, we have a lot of jazz (according to the Tzanetakis dataset), electronic music (according to the Dortmund dataset), ambient (according to electronic dataset) and an equal distribution of all generes Rosamerica dataset (which does not include a category for electronic music)….Not very clarifying then! This is definitely something that we will be looking at in more depth.
WHAT ABOUT MOOD THEN?
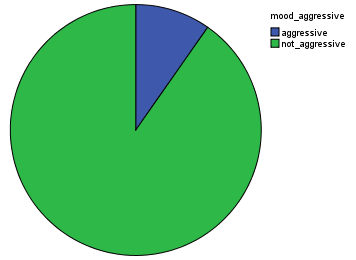
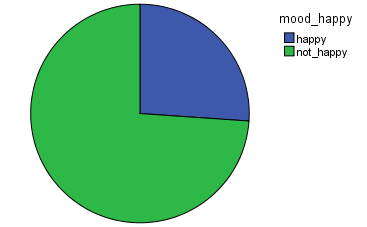
For Mood characterization, 5 different binary models were trained and computed on the dataset. We observe that there is a larger proportion of non-acoustic music, non-aggressive, and electronic. It is nice to see that most of the music is not happy and not sad! From this and previous study, I would then conclude that there is a tendency in the AcousticBrazinz dataset for electronic music.
Distribution of accoustic and non-accoustic (e.g. electronic) musicHow aggressive our dataset is
The amount of electronic music (compare with the acoustic graph above)
…and if the music is happy or not
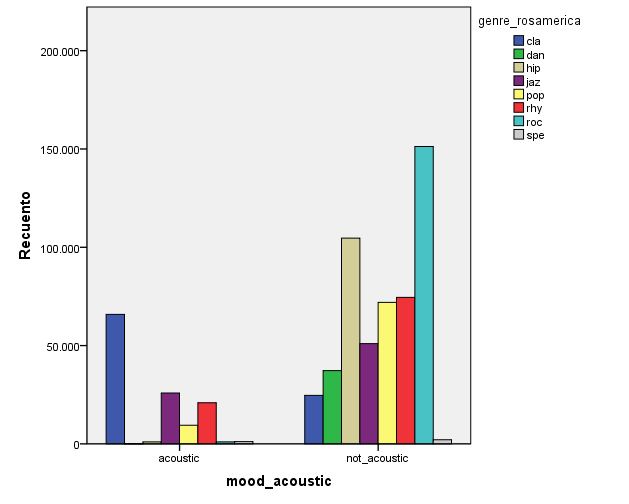
If we check for genre vs mood interactions, there are some interesting findings. We find that Classical is the most acoustic genre and rock is the least acoustic genre (due to its inclusion of electronic instruments):
How much music in each genre is accoustic or not
HOW IS KEY ESTIMATION WORKING?
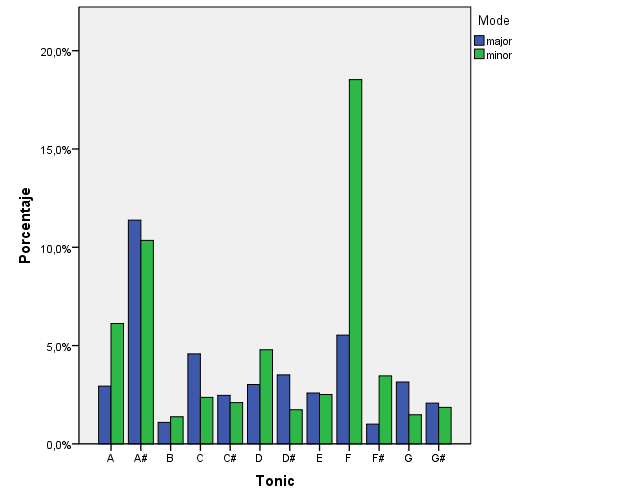
From a global statistical analysis, we observe that major and minor modes are both represented, and that the most frequent key is F minor / Ab Major or F# minor / A Major. This seems a little strange; A major and E major are very frequent keys in rock music. Maybe there are some issues with this data that need to be looked at.
The keys and modes of the tracks in the database
IS THERE A LINK BETWEEN FEATURES AND GENRE?
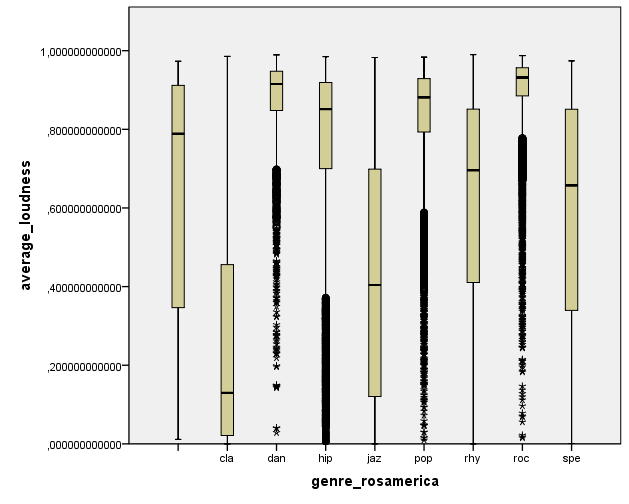
I wanted to do some plots on acoustic features vs genres. For example, we observe a small loudness level for classical (cla) music and jazz (jaz), and a high one for dance (dan), hip hop (hip), pop, and rock (roc).
The loudness of songs by genre
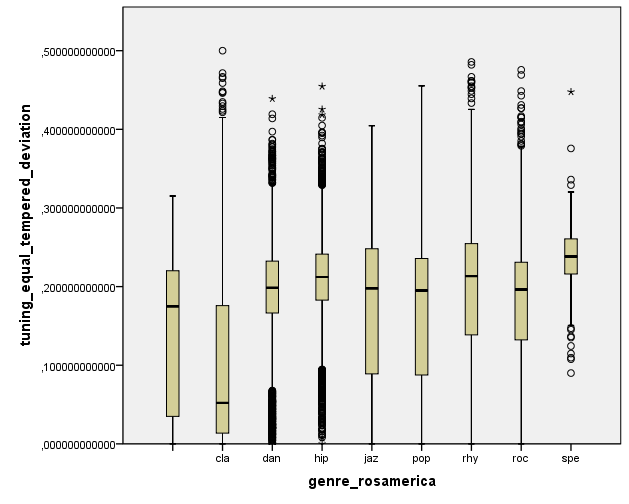
Finally, it is nice to see the relation between equal-tempered deviation and musical genre. This descriptor measures the deviation of spectral peaks with respect to equal-tempered tuning. It’s a very low-level feature but it seems to be related to genre. It is lower for classical music than for other musical genres.
Variation from equal‐tempered tuning per genre
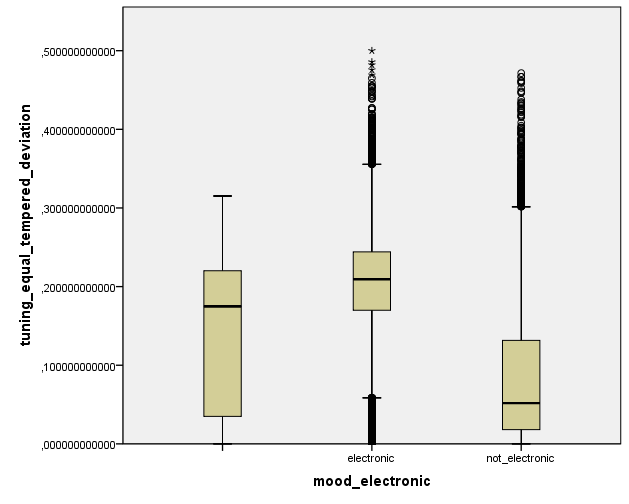
We also observe that for electronic music, equal tempered deviation is higher than for non-electronic music/acoustic music. What does this mean? In simple terms, it seems that electronic music tends to ignore the rules of what it means to be “in tune” more than what we might term “more traditional” music.
Variation from equal‐tempered tuning for songs reported as electronic/non-electronic
IS THERE A LINK BETWEEN FEATURES AND YEAR?
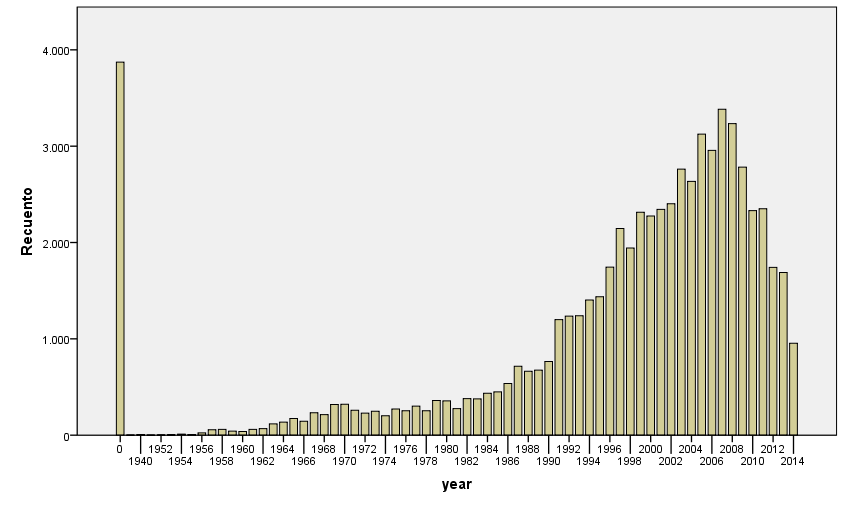
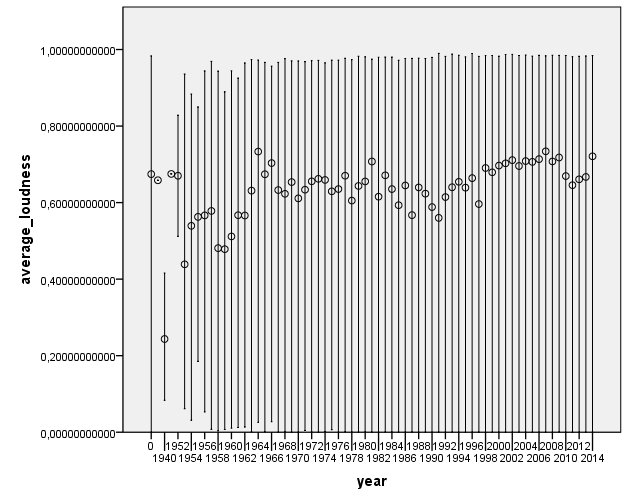
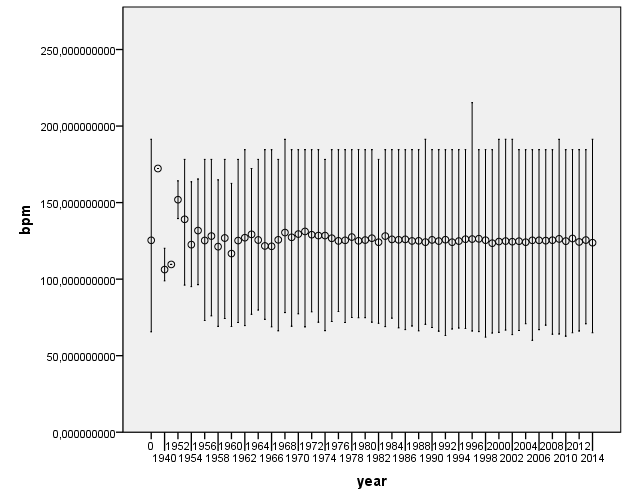
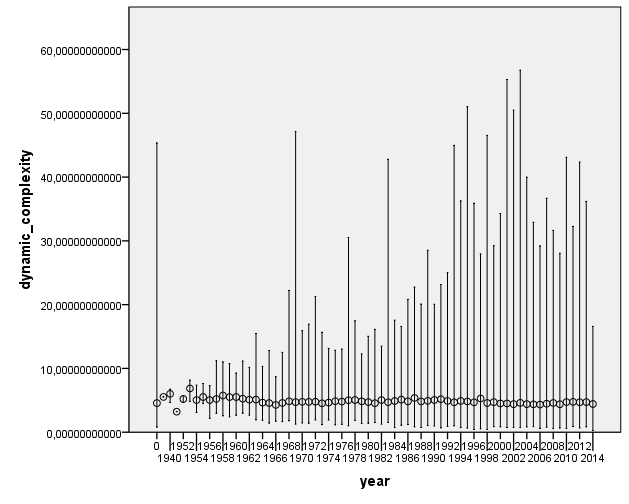
I was curious to check for historical evolution in some acoustic features. Here are some nice plots on the evolution of number of pieces per year, and some of the most relevant acoustic features. We first observe that most of the pieces belong to the period from 1990’s to nowadays. This may be an artifact of the people who have submitted data to AcousticBrainz, and also of the data that we find in MusicBrainz. We hope that this distribution will spread out as we get more and more tracks.
Distribution of release year for the dataset. 0 represents an unknown year
There does not seem to be a large change of acoustic features as year changes. This is definitely something to look into further to see if any of the changes are statistically significant.
Are the loudness wars true? Can you see a trend?Is music getting faster? It doesn’t look like itSongs aren’t geting more complex
We have many more ideas of ways to look at this data, and hope that it will show us some interesting things that we may not have guessed from just listening to it. If you would like to see any other statistics, please let us know! You can download the whole dataset to perform your own analysis at http://acousticbrainz.org/download
What is AcousticBrainz?
The AcousticBrainz project aims to crowd source acoustic information for all of the music in the world and make it available to the public. The goal of AcousticBrainz is to provide music technology researchers and open source hackers with a massive database of information about music.
AcousticBrainz uses a state of the art research project called Essentia (http://essentia.upf.edu/), developed over the last 10 years at the Music Technology Group.
Data generated from processing audio files with Essentia is collected by the AcousticBrainz project and made available to the public under the CC0 license (public domain). In 6 weeks since its inception, AcousticBrainz contributors have already submitted data for 650,000 audio tracks using pre-release software.
Today we are releasing client programs to submit data to the AcousticBrainz server and our first public release containing audio features for over 650,000 audio files.
What data does it have?
AcousticBrainz contains information called audio features. This acoustic information describes the acoustic characteristics of music and includes low-level spectral information such as tempo, and additional high level descriptors for genres, moods, keys, scales and much more. These features are explained in more detail at http://acousticbrainz.org/sample-data
What can I do with it?
We hope that this database will spur the development of new music technology research and allow music hackers to create new and interesting recommendation and music discovery engines. Here are some ideas of things we would like to see:
Music discovery
Playlist generation
Improving the state of the art in genre recognition
Analytics on the musical structure of popular music
and more!
This is one of the largest datasets of this kind available for research, and the only one of this size that we know of which contains both freely available data as well as the reference source code used to compute the data.
How can I contribute? If you are a music researcher, you can help us by contributing to the essentia project. Go to the essentia homepage to see how you can do this. If you do something cool with the data let us know. We’d like to start a “made with AcousticBrainz” page where we will showcase interesting projects.
If you have any audio files, we would love for you to contribute audio features to our project. You can do this by downloading our submission clients from http://acousticbrainz.org/download. We provide clients for Windows, Mac, and Linux.