
Hot on the heels of our release of the first 650,000 feature files as part of the first release of AcousticBrainz, we are presenting some initial findings based on this dataset.
We thank Emilia Gómez (@emiliagogu), an Associate Professor and Senior Researcher at the Music Technology Group at Universitat Pompeu Fabra for doing this analysis and sharing her results with us. All of these results are based on data automatically computed by our Essentia audio analysis system. Nothing was decided by people. Isn’t that cool?
The MTG recently started the AcousticBrainz http://acousticbrainz.org/ project, in collaboration with MusicBrainz. Data collection started on September 10th, 2014, and since then a total of 656,471 tracks (488,658 unique ones) have been described with essentia. I have been working for a while with audio descriptors and I followed the porting some of my algorithms to essentia, especially chroma features and key estimation. For that reason, I was curious to get a look this data. I present here some basic statistics. I computed them with the SPSS statistical software.
WHICH KIND OF MUSICAL GENRES DO WE HAVE IN THE COLLECTION?
In order to characterize this dataset, I first thought about genre. In essentia, there are four different genre models: trained on the data by Tzanetakis (2001), another one compiled at the MTG (Rosamerica), Dortmund and a database of Electronic music. Far from providing information on the kind of musical genres, these models seem to be contradictory! For example, in the Tzanetakis dataset “jazz” seems to be the most estimated genre, while the proportion of jazz excerpts is very small in the other models.
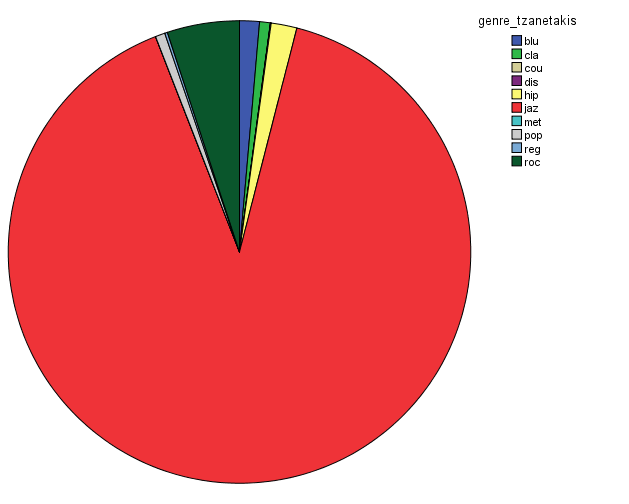
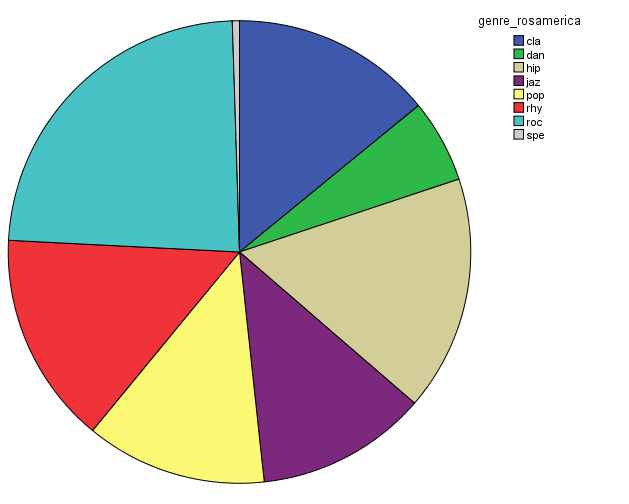
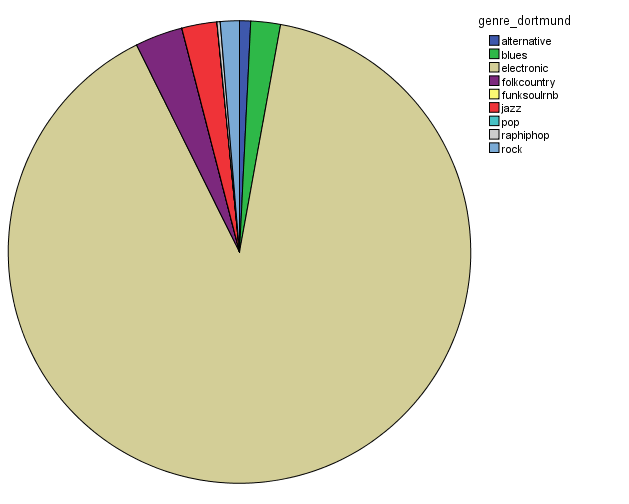
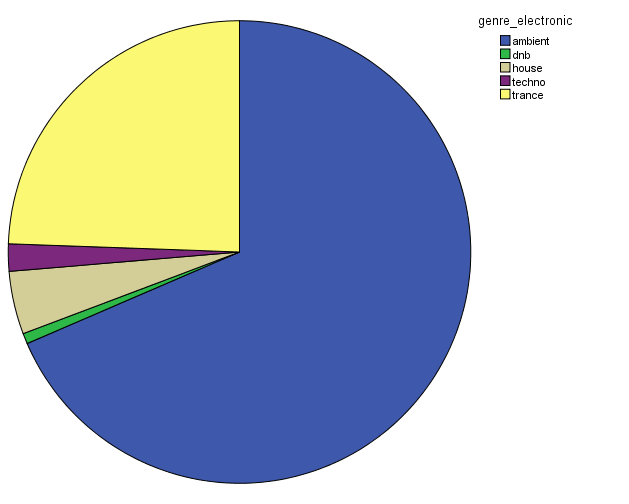
So in conclusion, we have a lot of jazz (according to the Tzanetakis dataset), electronic music (according to the Dortmund dataset), ambient (according to electronic dataset) and an equal distribution of all generes Rosamerica dataset (which does not include a category for electronic music)….Not very clarifying then! This is definitely something that we will be looking at in more depth.
WHAT ABOUT MOOD THEN?
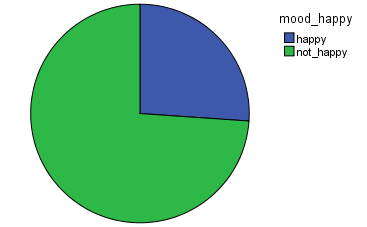
For Mood characterization, 5 different binary models were trained and computed on the dataset. We observe that there is a larger proportion of non-acoustic music, non-aggressive, and electronic. It is nice to see that most of the music is not happy and not sad! From this and previous study, I would then conclude that there is a tendency in the AcousticBrazinz dataset for electronic music.

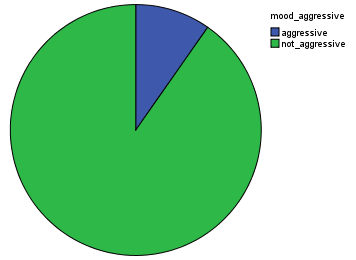

The amount of electronic music (compare with the acoustic graph above)
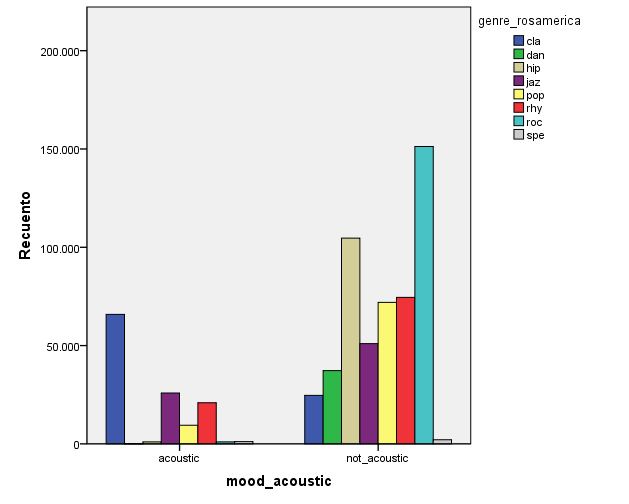
If we check for genre vs mood interactions, there are some interesting findings. We find that Classical is the most acoustic genre and rock is the least acoustic genre (due to its inclusion of electronic instruments):
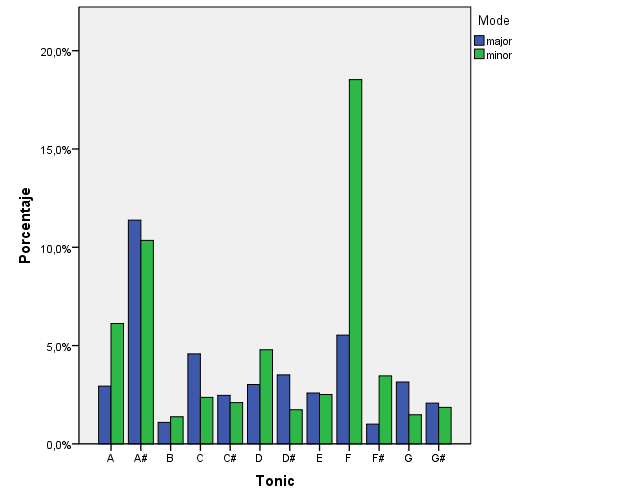
HOW IS KEY ESTIMATION WORKING?
From a global statistical analysis, we observe that major and minor modes are both represented, and that the most frequent key is F minor / Ab Major or F# minor / A Major. This seems a little strange; A major and E major are very frequent keys in rock music. Maybe there are some issues with this data that need to be looked at.
IS THERE A LINK BETWEEN FEATURES AND GENRE?
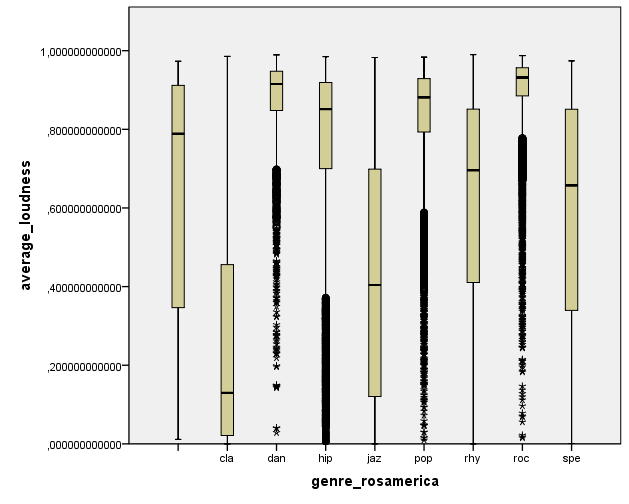
I wanted to do some plots on acoustic features vs genres. For example, we observe a small loudness level for classical (cla) music and jazz (jaz), and a high one for dance (dan), hip hop (hip), pop, and rock (roc).
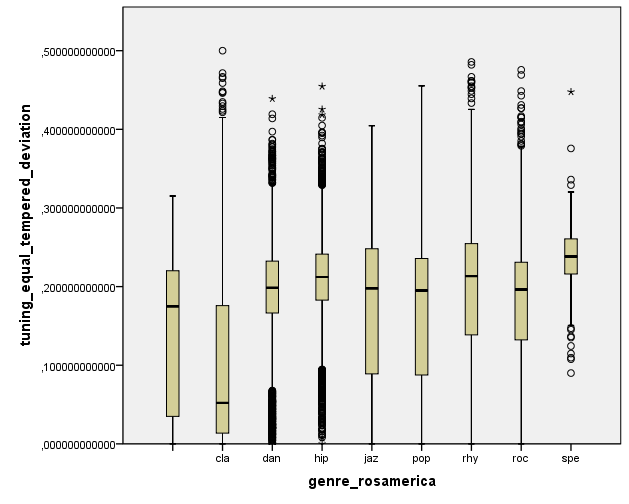
Finally, it is nice to see the relation between equal-tempered deviation and musical genre. This descriptor measures the deviation of spectral peaks with respect to equal-tempered tuning. It’s a very low-level feature but it seems to be related to genre. It is lower for classical music than for other musical genres.
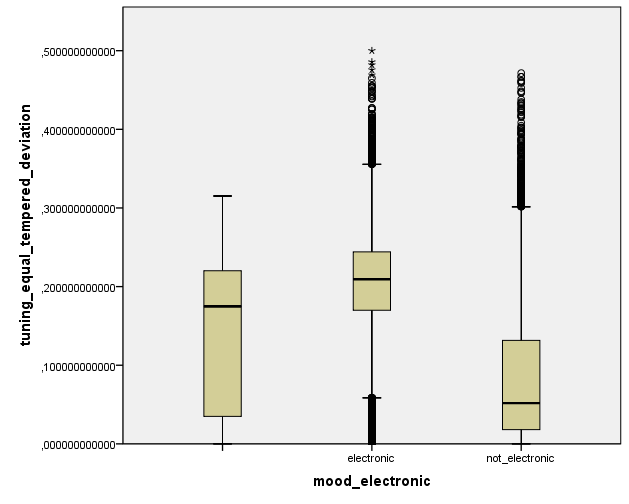
We also observe that for electronic music, equal tempered deviation is higher than for non-electronic music/acoustic music. What does this mean? In simple terms, it seems that electronic music tends to ignore the rules of what it means to be “in tune” more than what we might term “more traditional” music.
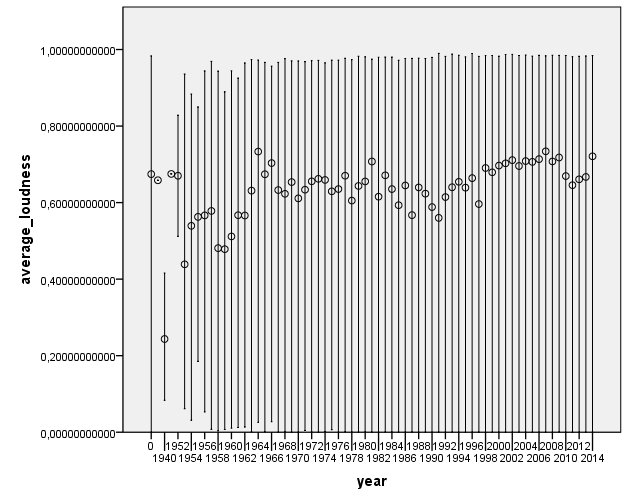
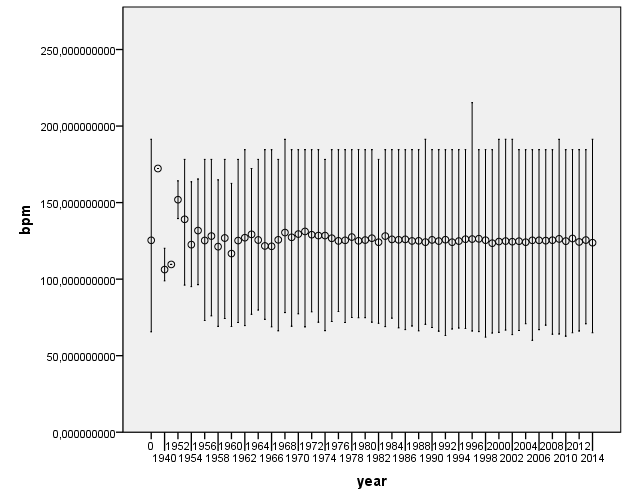
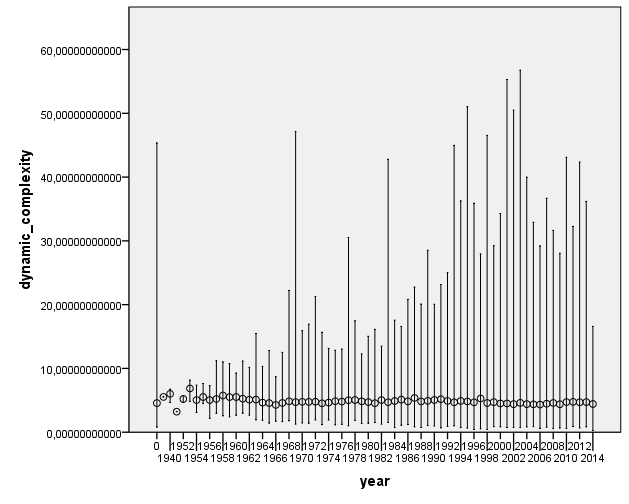
IS THERE A LINK BETWEEN FEATURES AND YEAR?
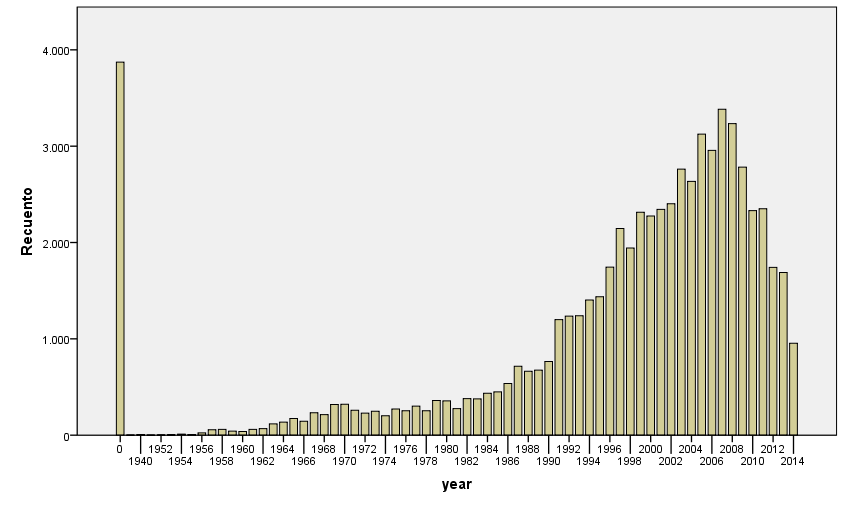
I was curious to check for historical evolution in some acoustic features. Here are some nice plots on the evolution of number of pieces per year, and some of the most relevant acoustic features. We first observe that most of the pieces belong to the period from 1990’s to nowadays. This may be an artifact of the people who have submitted data to AcousticBrainz, and also of the data that we find in MusicBrainz. We hope that this distribution will spread out as we get more and more tracks.
There does not seem to be a large change of acoustic features as year changes. This is definitely something to look into further to see if any of the changes are statistically significant.
We have many more ideas of ways to look at this data, and hope that it will show us some interesting things that we may not have guessed from just listening to it. If you would like to see any other statistics, please let us know! You can download the whole dataset to perform your own analysis at http://acousticbrainz.org/download
I’m working though my collection!
Something is wrong with one of your plots. dynamic_complexity error bars (assuming thats what they are), appear to follow your sample size preeetty closely. This implies there is a correlation between sample size and the distribution of dynamic compleixty, which there definitely should not be.
I guarantee that the horses are running wild here, especially for genre and mood (http://ieeexplore.ieee.org/xpl/articleDetails.jsp?arnumber=6847693). It is unfortunate to see effort being spent on the automatic creation and distribution of music description that run contrary to the aims of content-based MIR, i.e., “to make music and information about music easier to find” (Casey et al. 2008). For instance, here is an atonal female tango, http://acousticbrainz.org/533007ac-f407-4161-a6cc-e02ea064605a. Certainly, there are some interesting ethical questions here, e.g., should one knowingly employ a horse to describe an artist’s work? Will the next ten years be more of the same (http://www.tandfonline.com/doi/abs/10.1080/09298215.2014.894533)?
Bob,
Thanks for your comments.
Obviously you feel very strongly about accurately describing music. Have you met the MusicBrainz team before? This is the biggest group of music nerds I’ve met, including who you find at ISMIR. We’re all passionate about describing and understanding music. This is just our next step in an open process.
It is nice to confirm how considering large repertoires strongly influence current MIR methods. As you pointed out, we are now experiencing that machine learning models trained in specific repertoires (e.g. key in classical music, genre in ballroom music, or mood in specific genres) fail when applied to varied kind of musics. We are also observing how different audio formats may influence music features. Our next step is to investigate how these models can be adapted to different music material and exploit low-level features for that.
You know very well exactly what the ballroom training set represents. I agree, it has no place on information about this Tom Waits piece. We’ve had a previous question related to this too – “Why does your system not say that The Firebird is danceable when it’s a ballet?”. Putting aside concerns about the quality of the training set or the use of such datasets to describe these characteristics, we need to be smarter about using these descriptors to make claims about music.
We now have one of the largest open feature datasets in the MIR community. We’d love for you to jump in and see what you can make of the data. Are our low-level features sufficient to work towards our goals? I know you have experience with social descriptors such as last.fm tags from your previous work in genre datasets. If we can make a large, well designed training set will it be useful for the community? This is only the beginning of what will be an ongoing process to improve our data and the way we go about MIR research. Please help us answer these questions.
Dear Alastair, Thank you for your great response. How can I meet the MusicBrainz team and help answer those difficult questions? Also necessary is a thorough treatment of assumptions at all steps of the process. I am moving to London in about a month to take a position at QMUL. 🙂
BTW, I listed to the “tango” – you could well dance a Viennese waltz to it. 🙂
Bob,
Will you be at Music Hack Day London on the Dec 13 and 14? A number of us from MusicBrainz and MTG will be attending, and we’ll bring a copy of the database. If you will be around it’d be great to talk. Otherwise Barcelona and London are close enough that we could sort something out soon.
I won’t be attending Music Hack Day London, but I will be arriving Dec. 14 after noon to attend the Digital Music Research Network on Dec. 16! Maybe we can meet for beers at Brew Dog in Shoreditch after the hackday ends? 🙂
Are you considering Release Year or Release Original Year ?
There is a big difference between them and I think Original Year is more relevant for this statistics.
I’m submitting my whole collection but the statistics in the http://acousticbrainz.org/statistics-graph seem wrong.
Yes, we are aware of this issue with statistics and trying to figure out what’s causing it.
A problem with the loudness graph is that our recordings are merged throughout various masters and thus old years in the graph is IMO showing loudness values from more recent masters. :/