Many artists, especially the ones starting out, often do not realize the value of correct metadata and the various ins and outs of music metadata. In this 3 part series we’ll dive into why metadata is important and what artists can do to improve the metadata for their own music.
I highly recommend this article series. Stay tuned!
Anyone wishing to participate in the program should carefully read the terms for contributors and if you are eligible, go ahead and take a look at our Summer of Code landing page where you can find our project ideas that we listed for this year. Our landing page will tell you what we require of our participants and how to pick up a project.
Good luck to all who are interested in participating!
As you might know, here at MetaBrainz we’re rather picky when it comes to data. And we’re not exactly thrilled when Spotify’s Wrapped reports appear in December and then only contain data from the first 9 months of the year. Shouldn’t that be Spotify Three Quarters Wrapped?
We prefer properly baked solutions, and for that reason we’ve decided that we will wait until 4 January 2023 before we release our ListenBrainz Year in Music (YIM) reports. This way we can have one comprehensive report that includes all of your listens and all of the report data we derive from those listen.
If you are interested in getting your own version of our fetching Year In Music reports, we encourage you to sign-up and import your data before the year is done. Then in the first few days of January we will process this data into your complete report and publish it on 4 January.
In the meantime, have a look at last year’s YIM report. If we generated one for you in 2021, you can find that report from the Explore menu on listenbrainz.org!
This year’s report will be even better based on the feedback we’ve received from you!
We’re looking forward to getting these reports to you and we wish you happy holiday and a pleasant end of the year!
This year’s Google Summer of Code participant selection process created a situation that we’ve never encountered before: Two participants put in excellent proposals for the same project and both participants did a very good job of engaging with the community. But there was one difference between the two — one participant had engaged with us months earlier, written a whole new feature, saw it through the release process and got the feature into production.
This compelled us to accept the participant with whom we had already built a rapport. But collectively we felt really really bad about the fact that the other participant, Chinmay Kunkikar, would be rejected from Summer of Code and not work with us.
Fortunately we had recently earned 15,000GBP from our participation in the ODI Peer Learning Network 2, which we decided to spent on contributions to Open Source and musicians that our team loves. When the suggestion came up that we could create an internship on the spot that more or less follows the concept of Summer of Code, and that we could take on Chinmay and knock out yet another project during the summer, we jumped on the idea.
And with that I am pleased to announce that Chinmay will take on the “Upcoming and new releases page” project for ListenBrainz. This project will show a timeline of upcoming music releases and releases that have been recently released, complete with the ability to play these releases in the page.
Our team feels strongly about Chinmay as well as this new feature, so we’re excited that we’re taking on this 8th participant for this summer.
I am pleased to announce that long time contributor and complainer about our UI/UX, Simon Hartman, AKA aerozol has joined our team as a part time designer!
While we are starting with a very modest 3 hours of his time per week, we feel that this marks a rather important step forward for our team. While we now have two team members who have UX/design skills (Monkey and Akshat), they also carry a significant load of engineering tasks working on their respective projects.
Having Simon as part of our team will allow us to carve out concrete design tasks for him to focus on. Simon and Akshat will also revive our long dormant design system, which lets us create UI components that are intuitive and consistent. Our engineering team will be able to re-use these components across our sites, simplifying the future development of new pages. We hope that this shared design system will improve the user interface across all of our sites, with a strong focus on bringing the MusicBrainz UI into the modern age.
Having concrete help on the design front has been needed badly for a long time, which makes me very excited to welcome Simon to our team. Welcome!
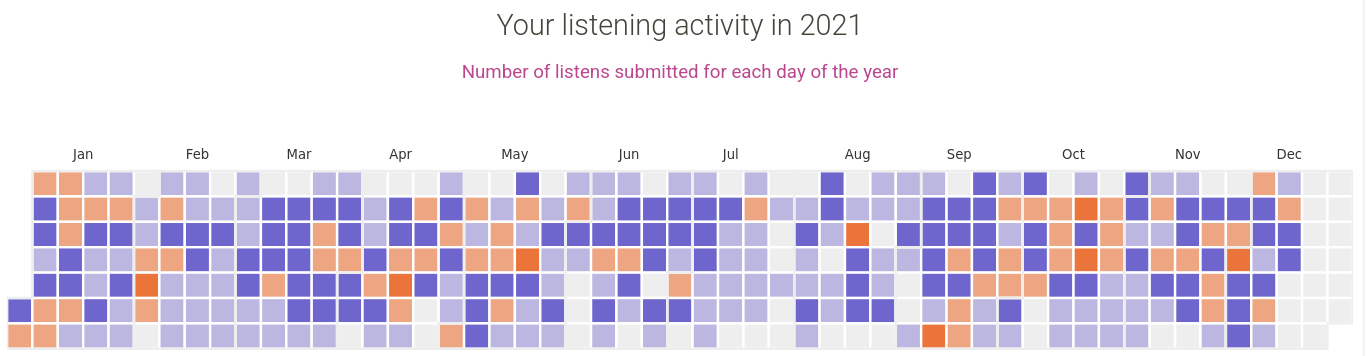
The ListenBrainz team has been wanting to provide a retrospective for its users for a few years now and this year we finally had enough resources to make it happen!
The Year in Music report includes a list of your top 50 releases for 2021, presented with cover art:
It also includes top lists, such as Your 50 most played songs of 2021 and Your top 50 artists of 2021 and spiffy map of your listening activity for 2021:
We also created 4 playlists for you to enjoy a retrospective of 2021. Three of these playlists aim to be playlists that feel comfortable for you, made up of tracks that you listened to this year. The Top Missed Recordings playlist, however, is a discovery playlist made from popular recordings that users similar to you listened to, but you didn’t. We make no guarantees that this playlist won’t give you at least little bit of iPod whiplash, which is why we’re presenting it as a discovery playlist that will require a bit more of your attention. However, don’t be discouraged—we’ve gotten a lot of positive feedback about this playlist!
And, this is not all yet—there are more things in the report for you to discover!
We invite you to head over to ListenBrainz to see if we were able to generate a Year in Music report for you. If not, please consider signing up for an account and sharing your listening history with us, so we can create a report for you next year! (You could also take a look at the reports generated for our team: akshaaatt, alastairp, amCap1712, mr_monkey, rob)
Happy listening and happy holidays from all of the MetaBrainz team!
I’m pleased to announce that we are continuing our long tradition of hiring our best Google Summer of Code participants — I’d like to warmly welcome Akshat Tiwari to the MetaBrainz team!
Akshat has been working on our Android App, continuing the work from last summer to improve the app and to add new features. He has been doing great work and demonstrating the fact that he understands user interfaces and has an eye for design as well as coding. This is a rare combination of talents and since we’ve been in dire need for improving the UI/UX for the MusicBrainz web site since forever, this was the time to finally get this project moving seriously.
Akshat has joined us on a trial contract through the end of the year with the goal of creating a new home page for MusicBrainz (and more hopefully) — the current home page is still stuck in the early 2000s and hasn’t evolved as our projects have evolved.
Starting with today’s update of the ListenBrainz server, we now require new account sign-ups to provide a valid and verified email in order to submit your listens. Existing accounts have until 1 November 2021 to meet this requirement, with users being reminded to add their email addresses when they log in. To avoid losing listens come November, we urge you to add an email address to your account now.
We dislike taking this step, but sadly we’ve seen an uptick of spam listens (why???) being submitted to ListenBrainz. Having a verified email address will deter some people from submitting spam listens, but most importantly it allows us to contact users about their listen histories. Sometimes it can be hard to judge if someone’s listening history is not particularly diverse or if they are a spammer.
Having an email allows us to contact users whom we suspect of spamming, ensuring that we don’t delete valid user profiles.
Our friends over at Kendraio want to integrate the MusicBrainz API into their app and are offering a bounty to a developer to help them do it. Kendraio App is a low-code bi-directional dashboard data browser. The aim is to enable Kendraio App users (including music artists) to search and browse, and also upload information to MusicBrainz. Here’s a ready-made example of how easy it is to create Kendraio Flows that connect to our API.
And within Kendraio App they’ve built Kendraio Player, a proof-of-concept for a multi-service music streaming player using web monetisation technology, funded by Grant for the Web.
The timeframe is about 2 weeks — start any time from now. The bounty is $500 USD (paid out via https://opencollective.com/kendraio – so you need to have an account there to be paid – but that’s easy). Please answer their bounty by replying to their GitHub issue.
I’m pleased to announce that Kartik Ohri, AKA Lucifer, a very active contributor since his Code-in days in 2018, has become the latest staff member of the MetaBrainz Foundation!
Kartik has been instrumental in rewriting our Android app and more recently has been helping us with a number of tasks, including new features for ListenBrainz, AcousticBrainz as well as breathing some much needed life into the CritiqueBrainz project.
These three projects (CritiqueBrainz, ListenBrainz and AcousticBrainz) will be his main focus while working for MetaBrainz. Each of these projects has not had enough engineering time recently to sufficiently move new features forward. We hope that with Kartik’s efforts we can deliver more features faster.