Hello,
I am Pinkesh Badjatiya and I have been working on ListenBrainz as part of GSoC ’16. I was largely involved in implementing the most requested features in ListenBrainz.
I began my journey with MetaBrainz not long before the Final Organization list was out. I started with MusicBrainz but moved quickly to ListenBrainz, and have been working on it since then.
About the project
The project consisted of creating a proxy scrobbling API similar to last.fm’s which could be used by existing desktop clients to submit listens to listenbrainz.org. I submitted my initial idea, that involved creating a new API along with few other optional features that were very much required (import, export, etc.).
The project made its way through the approval process, and I worked with ruaok (my mentor) & alastairp to get important things done. Yey!
Here are some of the snapshots of the my journey with ListenBrainz.
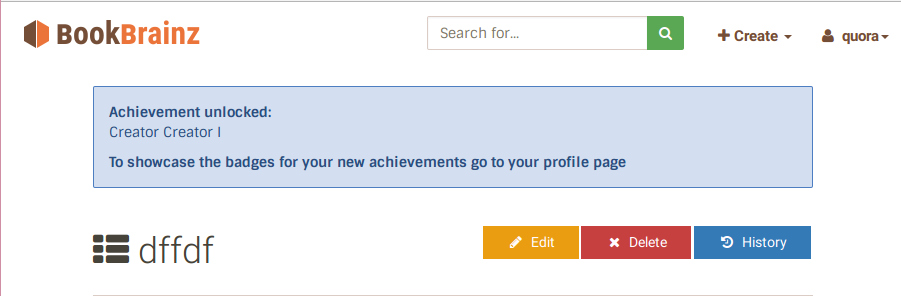
API_compat
ListenBrainz already had its own API which can be used to fetch/submit listens but all the existing clients that support scrobbling to last.fm use the ws.audioscrobbler.com’s API. To add support for these clients, I ended up creating a proxy API, api_compat (as in “compatible API”), that translates every request that is sent to “api.listenbrainz.org/2.0/” in the native format. This is an additional API which can be used along with the existing native ListenBrainz’s API.
This was largely the main goal of my project proposal. The instructions for scrobbling using Audacious are attached along with the source code.
Import lastfm-backup
The import page now allows users to import listens from the last.fm scrobbles or from the backup file which was downloaded from the older version of the last.fm website.
 On successful import of listens from backup, you’ll get the following notification.
On successful import of listens from backup, you’ll get the following notification.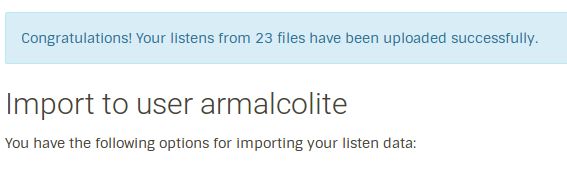
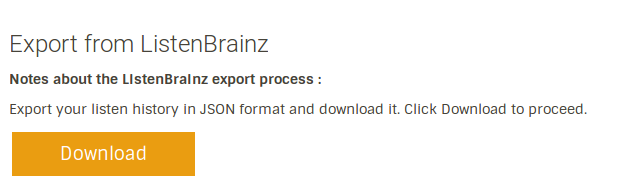
Export listens
This allows users to export the listens from the listenbrainz.org website. This is useful for users who want to keep track of their listen history offline as well.
The export feature can be accessed from the drop-down menu.
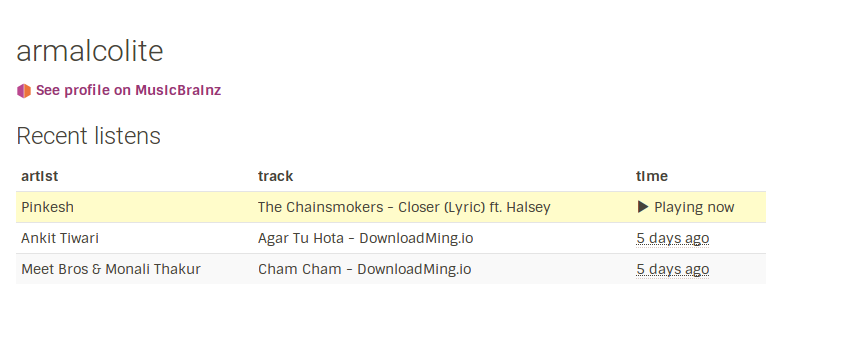
Playing Now
With the support for API-Compat, the support for currently playing song was needed. This keeps the currently playing song on the website in sync with your favourite player.
Import scraper uses audioscrobbler API
I also worked on updating the import scraper which now use the ws.audioscrobbler.com‘s API allowing users to import without opening their last.fm profiles. This also provides other useful track information to ListenBrainz.
Migrate to PostgreSQL
Another important change to ListenBrainz was how it stored listens. We moved from using Cassandra to PostgreSQL. Cassandra was fast and effective but getting more information other than the user’s listens (ex. generating statistics) was not possible. So we switched to Postgres + Redis. This opened more possibilities for future.
Experience
After 3.5 months, I ended up with 15 merged and 3 closed PR’s and a bunch of features for ListenBrainz that improved its look and feel.
My pull requests: https://github.com/metabrainz/listenbrainz-server/pulls?utf8=%E2%9C%93&q=is%3Apr%20author%3Apinkeshbadjatiya%20
I have worked on quite a lot of varied things in the past 4 months. A lot of them were actually not the part of the GSoC proposal but they were done largely in the same timeline or were optional targets, so I suppose they would count significantly towards GSoC.
I worked largely with alastairp, ruaok and Gentlecat. Gentlecat helped improve my coding style by providing feedback on my PR’s. I worked with alastairp and ruaok regarding the ideas/suggestions on how to address a problem and its possible solutions. It was a interesting experience working with the community and getting to know about MetaBrainz. Now that my understanding of the project and the community has increased, I look forward to making some great contributions!
Conclusion
In short, ListenBrainz went through a hell lot of changes in the past 4 months. If you were waiting for it to improve before using it, then now is the time that you should try it. I bet you’ll love its new look and you won’t be disappointed. 😀