
Hi everyone!
I’m Shivam Tripathi, an undergraduate student from the Indian Institute of Information Technology, Una. I interned for the MetaBrainz foundation under the Google Summer of Code programme for the year 2018 and worked on the BookBrainz project. I was mentored by Ben Ockmore during this period. This post summarizes my contributions to the project and experiences that I had throughout the summer trying to solve various problems related to the implementation of the project.
Proposal
The original proposal I submitted to Google underwent some modifications as the project progressed, details of which can be found later in this post.
Community Bonding
Summer of Code started with the community bonding period – during which I attended the regular Monday meetings at MetaBrainz’s IRC channel #metabrainz and interacted with the MB community members. I added multiple new entities to the BookBrainz’s website and helped some users with BookBrainz related queries on the community page (intended for support/general QA related to all of MetaBrainz projects).
Also during this period, my mentor Ben Ockmore and I discussed and finalized the architecture of the importer application. It was decided to split the entire importer into two microservices: one for producer (which reads the data dumps and produces generic objects for each record using BookBrainz data storage format) and the other of consumer (which reads and validates the generic object and then insert them into the BB database). It was decided to connect these microservices using a message broker queue (RabbitMQ was finalized). In addition to this, the code repository architecture was decided to be such that we should be able abstract away the entire message broker logic, so that later it would be possible to swap out RabbitMQ with any other hosted service later (like pubsub).

Fig. 1: Initial design of the intended importer application. For more information, visit the original document.
Coding period
First phase
The program coding period kicked off with making changes to the existing BookBrainz schema to enable it support our new imports. The initial design as discussed here was later updated to include views as well for imports per entity to enable simpler queries.
Following this, I started working on the bookbrainz-data repository to add some basic functions for aiding the import process. I started work in accordance with one of the existing roadmaps for the BookBrainz project which was to shift all database logic from bookbrainz-site to bookbrainz-data – adding features on a per-function basis. Initially it was decided to use Immutable.js for all data flowing in and out of bookbrainz-data-js, but very soon we realized that it was not practical to follow this approach. After some discussions, we finally settled on this repository design change to incorporate new function-oriented functionality. We named this new sub-module func.
Once I had basic functions to handle database transactions in place, I started working on the importer architecture. It was decided to create multiple instances of the producer process each with the ability to run asynchronous operations on it’s own. Similarly, we should be able to fork multiple consumer process, each capable of fetching data from queue and sending it off to the database.
To address this problem, I started working on a module which given a function would make it possible to run multiple processes running multiple instances of the given function. It should be such that we can generate the arguments dynamically for each process and along with some set-up and tear-down actions before and after we fork the process.
To get a better grasp of underlying functionality, one can read the final API and documentation. It’s a generic module which can be used for any functionality. The diagram for it’s execution flow can be found below:

Fig 2. AsyncCluster module execution flow. For more details, see the complete documentation.
Second phase
While developing producers, I first designed the generic producer object structure for all entity types – an object skeleton which all producers need to create from the read records to be pushed into the queue. This object structure was to be enforced across all data sources, and this helps the consumers to expect an object of fixed nature on which they can later run automated validation tests prior to adding to the database.
As the data dumps were of considerable size, I used data streams to read the data from the flat files and parsed them to create generic entity objects which used BookBrainz data storage format. After parsing each record, I pushed the records into the queue.
Parsing required thorough analysis of the data dumps, and manually mapping each key-value pair in the data dump to the generic object structure. All the data which did not fit the present BB schema (and hence had to be excluded from the generic producer object structure) was added to a metadata field associated with the import. This metadata field is stored as a bjson in the database, so that we can individually query and index any of the fields in the metadata later.
While developing the consumers, I initially set up a validation module. Much of it was adapted from the existing validators on BookBrainz site, which I was able to use without much alteration thanks to the generic producer object structure. The validation modules in the bookbrainz-site have been written to quickly validate the form submitted by the editor post creation/editing of an entity. To use them in the import process, I wrote a converter which transforms the generic producer object to form sections understood by the validation module. Apart from this, I added better error handling to ensure all errors are caught and reported in case a something goes wrong.
Error handling was another important aspect of the import process, apart from the validation process. Being a command line application, tracking errors was central to ensuring that all components were running as intended. At the same time we had to ensure that no record which could be potentially imported into the database was missed. To address these problems, I decided to discard the record if it fails the data integrity validation tests (which means the data is most probably corrupt). But in the case of any transaction error, we give a fixed number of chances to the record before discarding it (by acknowledging the message). A future goal for this process could be to push the erred record into another queue for analysis and replaying of those messages from this queue back to the original queue when the problem gets sorted.
Once the importer was in place, I focused on building up the func.imports module with more functions for the import entities – like discard and approve. I also added functions to fetch recent imports, and a lot other helper code for the imports. I also ensured that all errors occur loudly and never silently slip away. With the help of my mentor, I also migrated most of the functions required for data transactions on the bookbrainz-site. This was crucial to my project – as in many instances the existing functions could not be used due to them initiating their own database transaction for each action. I split all these actions into functions, and bound them with the transaction object they received rather than initiating their own transaction. I also ensured we use modern ES6 features – which made the adapted code much more sleek and compact. It was a long process, as I had to read almost entire of existing code for data transactions on the bookbrainz-site and adapt each of them correctly. All the code finally came together in the create-entity module – which can now be used for entity creation as well as upgrading the imports to entities.
Third Phase
The work on bookbrainz-site and bookbrainz-data mostly happened side by side. First I added a recent imports page – which would fetch most recent imports from the database and display them inside the React component. The recent imports is designed as a single page application which dynamically loads the paginated records and renders them on-screen. The working of the recent page application is as follows:
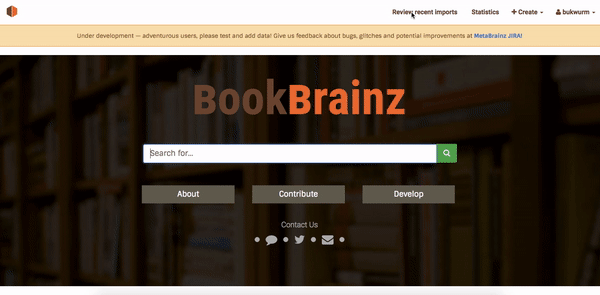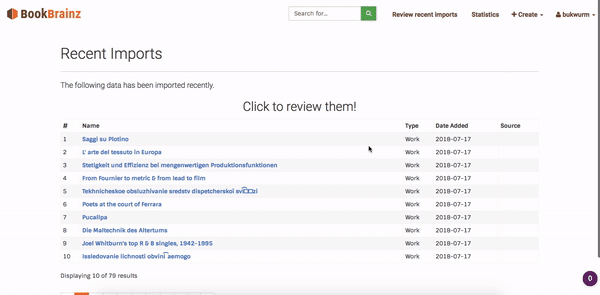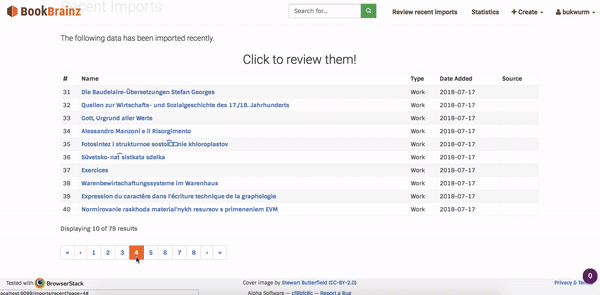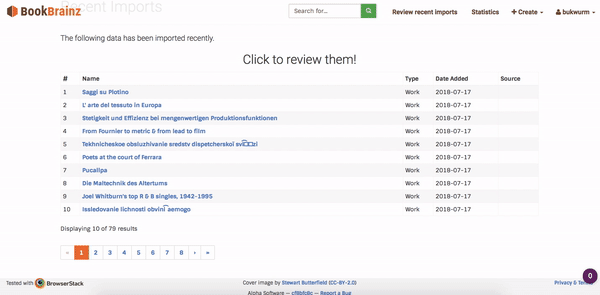
Fig. 3: Recent imports execution flow
Next, I added import-entity display pages for all five entity types. They were supposed to display the entity attributes along with links to approve/discard/edit and approve functionality. Approving the import-entity was done so that the user gets redirected to the newly created entity. The import-entity display page for work is as follows:

Fig. 4: Work Import Entity Page. Similarly, pages were added for Creator, Entity, Publication and Publisher.
In case of a discarded import, I added an extra page similar to existing confirm deletion page – which asks the user to confirm the action and then waits until the entity is deleted before redirecting the user to the home page. The discard page looks as follows:

Fig. 5: Discard Import Entity Page
Next, I implemented the editing imports prior to approval. For this, I wrote two modules – one to transform the import to the structure used by the editing form and one to convert form data to an entity. When a user wishes to edit an import, the import is transformed to the form and rendered on the screen. The user can then edit the import. When the user clicks submit, we transform the form data to a new entity type and use the create-entity function to create a new entity in the BookBrainz database. The user is then redirected to the newly created entity page. The code for rendering the form and editing the entity was completely reused for imports with minimal changes. I then added functionality to add imports to the ElasticSearch index, and display them in present results. The final search page is as follows:

Fig. 6: Search showing Import Entities
Links to the work done
Conclusion
Last three months have been a fantastic experience for me. Not only did I get to learn a lot of new technologies and write some exciting software, but also I got to brush up my existing skills and interact with the completely awesome MetaBrainz community. Such an opportunity comes truly once in a lifetime, and I extend my sincerest gratitude to Google for running such a great and extremely inclusive programme which allows students from all over the world to avail such an opportunity. Special thanks to my mentor Ben Ockmore for always being patient and helping me out whenever I felt stuck.
Thank you MetaBrainz community for your continuous guidance and support!
!m Google and MetaBrainz