Today’s MusicBrainz Server brings a new data report, a continued conversion to React, some bugfixes and small improvements, but also tests refactoring.
Meanwhile, the search server has been updated twice in a row to fix bugs in JSON output mostly with MB Solr 3.2 (release notes) and MB Solr 3.3 (release notes), including the MusicBrainz API breaking change announced last month.
A new release of MusicBrainz Docker is also available that matches this update of MusicBrainz Server. See the release notes for update instructions.
Thanks to amCap1712 for fixing bugs in MB Solr, and to loujine for contributing code with yet a new data report. Thanks to Avamander, bonchiver_, chaban, draconx, eloise_freya, GTF1982, hawke, hibiscuskazeneko, jesus2099, jrv, kellnerd, Kid Devine, Psychoadept, selflessself, and wcw1966 for having reported bugs and suggested improvements. Thanks to kellnerd, mfmeulenbelt, and salorock for updating the translations. And thanks to all others who tested the beta version!
Picard 2.5 Beta 1 is now available. This is a pre-release to gather final feedback on the changes before the final 2.5 release.
Thanks a lot to everybody who contributed to this release with code, translations, bug reports and general feedback.
What’s new?
This release fixes some possible crashes, makes Picard able to run on the new macOS 11, provides several small UI improvements, allows using file tags and variables in tagger script, and more. See below for a full list of changes.
Bugfixes
[PICARD-1858] – MusicBrainz Picard does not respond on macOS 11 Big Sur Beta
[PICARD-1882] – Scripting text not well readable with dark theme on KDE
[PICARD-1888] – Returning tracks to cluster uses matched release rather than what’s in the files
[PICARD-1932] – Failed AcoustID submission shows as successful
[PICARD-1939] – Crash when “Remove” button is hit without picking a file first
[PICARD-1941] – Unchanged multi-value tags on tracks show up as changed
[PICARD-1954] – Right-clicking on album with “could not load album” message crashes
[PICARD-1956] – It is possible to have the same file multiple times inside the same cluster
[PICARD-1961] – Capitalization for non-standardized instruments
[PICARD-1963] – Possible stack overflow when loading files
[PICARD-1964] – Scripting documentation does not support RTL languages
[PICARD-1969] – Browser integration port changes without saving options
[PICARD-1971] – Tags from file names dialog does not restore window size
New Features
[PICARD-259] – Make file-specific variables and metadata available to tagger script
Picard 2.5 beta 1 is available for download from the download page.
Helping out
The easiest way to help us getting a great Picard 2.5 release is using and testing this release candidate. Please report bugs on the Picard issue tracker and provide feedback in the community forums.
Please also help translate Picard. There have been many changes to the user interface and existing translations need to be updated for the final 2.4 release. Translating is easy and can be done online: Head over to MusicBrainz’s translation page on Transifex and click on “Help Translate MusicBrainz”. Once you have registered an account on Transifex you can start translating. For Picard the primary resource to translate is “picard“, but there is also the “picard_appstream” resource which is used for providing descriptions for various Linux software-center applications.
If you are a software developer you are very welcomed to provide fixes and features. Picard is free software and the source code is available on GitHub. See Developing on the Picard website to get started.
During the summit this past weekend we talked about posting more updates to our blog. In the spirit of that, I wanted to share two articles where MusicBrainz and AcousticBrainz were recently mentioned in the news: In July the BBC wrote an article covering research from UC Irvine in California:
They found a significant downturn in the positivity of pop songs. Where 1985 saw upbeat tracks like Wham’s Freedom, 2015 favoured more sombre music by Sam Smith and Adele.
The UC Irvine research team analyzed the publicly available data from AcousticBrainz to arrive at this and several other conclusions.
We also used song credit information from crowdsourced database MusicBrainz to determine how many women and men worked on the writing, production and performance of each song. . . . At first glance, our overall results appear quite simple. In line with past research on creativity, we find no baseline relationship between the novelty of the songs in our sample and the gender identity of the artists involved. Men and women appear to be equally capable in terms of creativity. But when we controlled for genre and, importantly, the gender composition of artists’ genres, the picture changed. Our methods were guided by an awareness that women in music work in a different context than men do: By a kind of gender-slanted gravitational pull, the music industry drives women into certain genres (e.g. pop) and collaborative networks.
We’ve long known about gender imbalances in the music industry and while we’re happy that people are using our data to demonstrate this, we’re dismayed at most of the findings in this article. What is more concerning is that we have a general impression that our community has a slight bias towards adding more information about music created by women, which means that the overall situation may actually be worse than what one can deduce from our data!
As a reminder, all data in MusicBrainz is contributed by members of the community. If you see any situations where women or minorities are being mis- or underrepresented, we encourage you to add this content to MusicBrainz. And if you get stuck, don’t hesitate to ask for help on the forums.
As we just returned from the virtual MusicBrainz Summit 20, here comes a mostly maintenance release that fixes a bunch of bugs (among which many are about localization) and provides a few handy improvements. It even features a new report showing releases having the same barcode but currently in different release groups, so if you feel like it, do try and help us look into those!
A new release of MusicBrainz Docker is also available that matches this update of MusicBrainz Server. See the release notes for update instructions.
Special thanks to the DistriNet Research Group for making and responsibly sharing a very detailed audit of our OAuth service that has been very helpful with releasing major security improvements in the previous server update!
Thanks to chaban, fabe56, hibiscuskazeneko, humhumxx, jesus2099, lotheric, mfmeulenbelt, nikki, otringal, psychoadept, and wcw1966 for having reported bugs and suggested improvements. Thanks to dimpole, listmycds, mfmeulenbelt, peter9811 for updating the translations. And thanks to all others who tested the beta version!
React conversion tasks are conspicuously absent from today’s release, but that’s just because we needed to take some time to get it all working with the recent refactoring. This new server update mainly brings strong security improvements for the OAuth service. It also comes with a fair amount of smaller bugfixes and improvements. The most noticeable of these probably are the added details to the merge recordings’ form and the statistics by entity type on editors’ profile pages.
Announcement for MusicBrainz API users:A small but breaking change will be deployed on October 19th (in one month from now), to fix the JSON formatting of release packaging in search results (SEARCH-579).
A new release of MusicBrainz Docker is also available that matches this update of MusicBrainz Server. See the release notes for update instructions.
Thanks to kellnerd and loujine for contributing code. Thanks to calculator.ftvb, chaban, hibiscuskazeneko, jesus2099, kellnerd, lalinksy, psychoadept, rdswift, and spitzwegerich for having reported bugs and suggested improvements. Thanks to jesus2099, kellnerd, mfmeulenbelt, outsidecontext, and salorock for updating the translations. And thanks to all others who tested the beta version!
Beyond the restless conversion to React of edits’ display, this new release of MusicBrainz Server features the sidebar display of recordings’ acoustic information automatically computed by AcousticBrainz, and brings a handful of more discreet improvements and fixed bugs.
A new release of MusicBrainz Docker is also available that matches this update of MusicBrainz Server. See the release notes for update instructions.
Thanks to loujine for contributing the code to display AcousticBrainz data. Thanks to chaban, draconx, hawke, scotia, and yindesu for having reported bugs and suggested improvements. Thanks to kellnerd, mfmeulenbelt, salorock, and speardog for updating the translations (de, el, fr, it, nl). And thanks to all others who tested the beta version!
This is another bugfix release for the 2.4 release series of Picard, fixing a couple of issues discovered since Picard 2.4.2 and updating the Spanish and Hebrew translations.
Due to a last minute fix we had both a 2.4.3 and 2.4.4 release today, below is the combined list of changes:
Bugfixes
PICARD-1916 – Picard crashes on older releases of macOS due to theming exception
PICARD-1918 – Saving files fails if there is no front image and “Save only one front image as separate file” is enabled
PICARD-1921 – Windows 10: With dark theme inactive checkboxes cannot be distinguished from active ones
PICARD-1928 – After clustering fingerprint icon disappears
PICARD-1931 – Regression: “Unmatched Files” do not appear when release was deleted from MB
Picard 2.4 is available for download from the download page. For Windows 10 users installing from the Windows Store an update will come automatically as soon as the new release has been approved by Microsoft.
Thanks a lot to all contributors who made this release possible.
I am Rohit Dandamudi, more commonly known as diru1100 in IRC and all other sites. I am currently doing my final year in Computer Science and Engineering at Chaitanya Bharathi Institute of Technology, Hyderabad. This summer, I had the wonderful opportunity to work with MetaBrainz Foundation and it’s my first time participating in GSoC. I worked on the SpamBrainz project under the guidance of yvanzo to make a step forward on eliminating spam in MusicBrainz.
How it started
I started looking for some cool projects to apply for GSoC, eventually, after going through some which were involved in the web development side, I finally got to know about the MetaBrainz Foundation, and it was already pretty late (around 2½ weeks before the proposal deadline), most of my fellow GSoCers were already in good rapport with the community by then. After looking through the project ideas, I wanted to do my project on CritiqueBrainz, but later I found out that it’s not considered for this year. In the end, I liked the concept of SpamBrainz and how it involves a good combination (Deep Learning and Web Development) of technologies. After browsing through the project I understood what I could and tried to make some changes to the codebase and was successfully able to run the model and add some documentation. Finally, I submitted the proposal, which got accepted.
Retrained the model with the simulation of taking spam as a non_spam account and it was able to predict the new learnings while still being able to remember the original non_spam accounts.
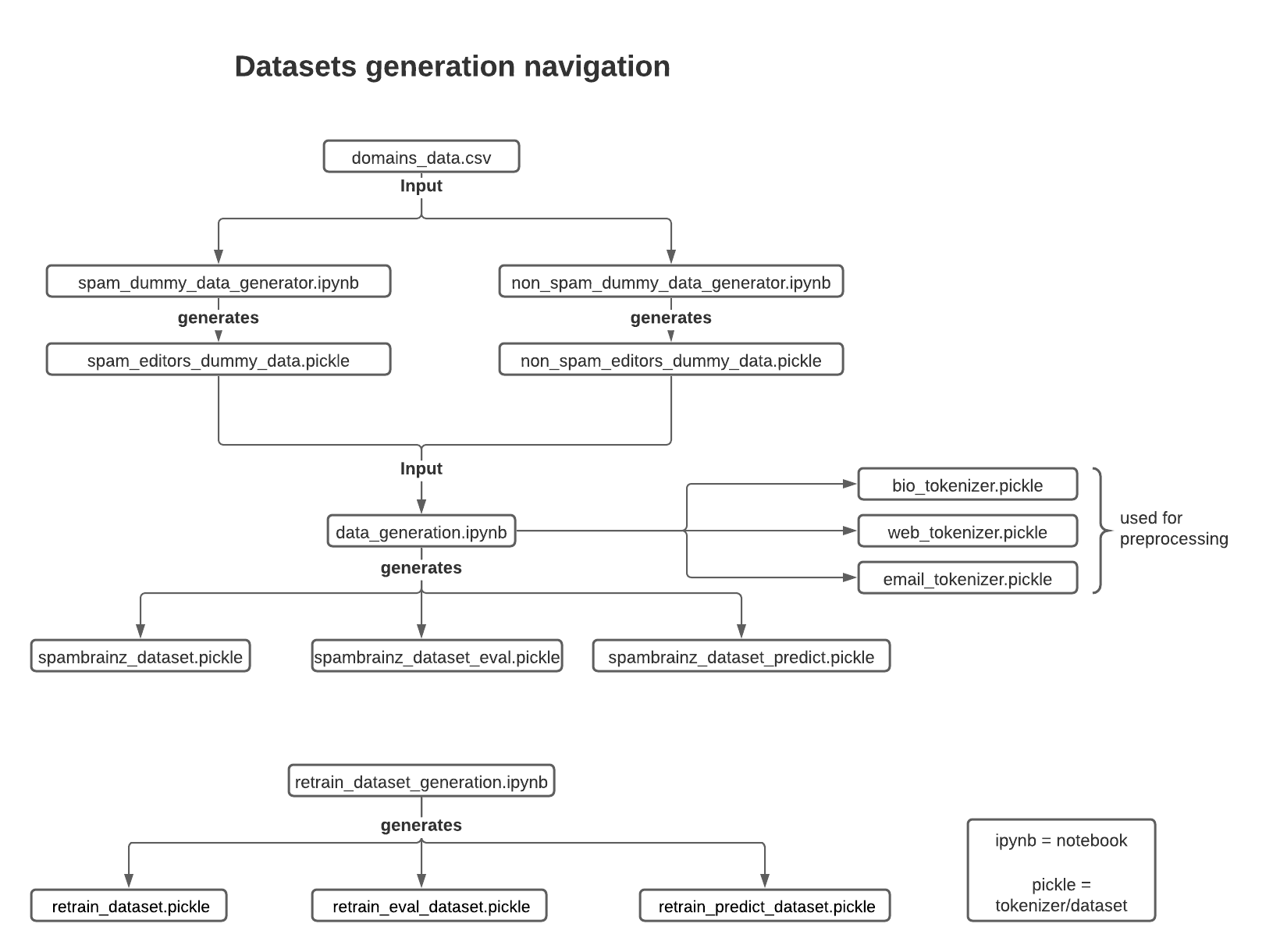
Here is a navigation diagram explaining which notebooks and datasets are connected and the relationship between them.
Research for model live update
To implement the online learning part I had to explore and test different methods with the generated dataset and LodBrok model. For this, I had to explore various resources such as Keras’ community forums, research papers, StackOverflow, courses, and blogs.
A few of the interesting findings I have tested out were:
Retraining the model
This seemed to be the most obvious and easy fix to upgrade the model.
Transfer Learning mainly involves deriving a new model from a pre-existing successful model (LodBrok) known as feature extraction to tackle similar cases.
I was inspired by the fine-tuning feature of Transfer learning which has a similar learning method as the one I implemented.
Online Transfer Learning (OTL)
This, as the name suggests is a combination of online learning and Transfer learning, which helps us to define models that can learn to classify similar spam accounts in MetabBrainz.
No need to store editor details for false-positive and false-negative cases respecting MetaBrainz’s data privacy rules.
The model won’t go through catastrophic forgetting (forget old learnings of what is spam or not) and will be able to learn new patterns in spam accounts over time.
The structure of the data isn’t changing over time (editor account fields remain the same).
/predict to return classification results by LodBrok for the editor accounts
/train to retrain the model with incorrect results sent to SpamNinja respectively
After discussing with Leo, I decided to implement the API using Flask and Redis combination. Going with Redis over RabbitMQ for this API is feasible as the API is pretty lightweight and has at most 2 events.
Documented the entire API, with internal working, steps to replicate, and images to understand the results obtained.
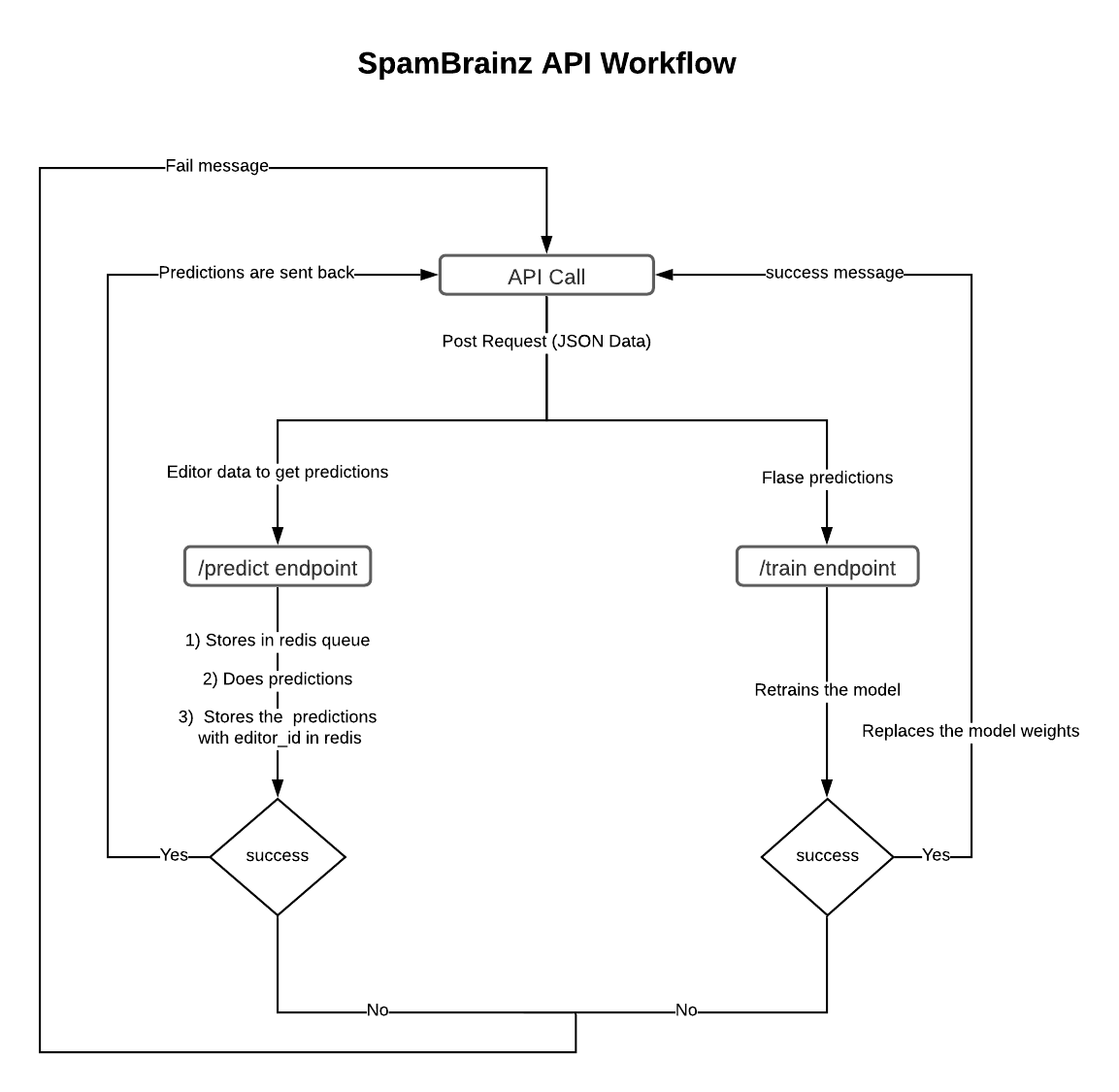
This diagram explains the current workflow of the implemented API:
Challenges ahead and future of SpamBrainz
The API has to be integrated with MusicBrainz and should undergo more testing with real live data, currently, my focus is on this part.
Note: All the work done till now on the model was on dummy data generated by scripts that tend to replicate the real accounts as much as they can be, by taking into account the inputs from Freso, yvanzo, and the analysis done by Leo, without affecting the data privacy policy.
To extend online learning to other use cases in MetaBrainz through Transfer Learning and Online Transfer Learning.
Also looking forward to writing a research paper about the work done, and eventually publish it in IEEE transactions, as I plan on using SpamBrainz as my final year major project.
Special thanks to…
My mentor, YvanZo for being incredibly patient with me, helping me create quality commits, and overall making me a better programmer. Have always learned something new in every interaction with him.
LeoVerto, for helping me out whenever stuck and getting me up to date with the project.
MetaBrainz Foundation, for creating an open, inclusive, and productive environment to build some amazing stuff.
Hi everyone, I am Prabal Singh currently studying in Indian Institute of Technology, Guwahati. This summer I participated in Google Summer of Code and developed a new feature – User Collections – for the project BookBrainz.
Hey! My name is Shivam Kapila (shivam-kapila on IRC) and I am a final year undergrad at National Institute of Technology Hamirpur. I have been working on the ListenBrainz project this Summer as a participant of the Google Summer of Code program. The past four months were full of fun, hacking and loads of music!!
Landing into the MetaBrainz Community!
My journey with MetaBrainz began in late January this year, when I introduced myself to the community. My first PR improving the developer documentation was by adding parts connected with setting up the Spark infrastructure on a local setup along with consolidating and improving bits of documentation. I delved into real code while implementing front end components for Deleting Listens. Over the next few months, I fixed various bugs like making the Importer Modal responsive, fixing the DB setup scripts, fixing pagination issues while browsing listens, handling stat calculation errors in the Spark Reader and flushing user stats when they delete their listens.
As a GSoC applicant, I proposed to add various Listen Management features like love/hate (aka feedback) and deleting individual listens in ListenBrainz. I also proposed a new design for the Listens page. This involved a lot of designing and research, going through UI/UX design guidelines and tuning colors, shades and shadows till we arrived at a presentable and subtle design.
And finally I onboarded the GSoC train 🙂 .
Bonding with the community
I had been a part of the community since January so I was familiar with how things work in ListenBrainz. So I decided to contribute to the TimescaleDB migration where we moved our primary listen store from InfluxDB to TimescaleDB, opening up a ton of features for us to work on. Here is the final migration PR containing the commits of my contribution.
As the official coding period began, I started working on my proposed tasks. The first question was: how to store the feedback? So I began implementing the database changes to store the recording feedback and applying the necessary changes in production. Following this I added a Python module to interact with the database and implemented a Pydantic model to validate the feedback records before they are stored in the database or served over the API. Then I added the necessary APIs to store and fetch the feedback for a given user or recording. This was followed by improving the efficiency of the DB module.
I also worked on dumping the recording feedback in the ListenBrainz public dumps. Since ListenBrainz had migrated the stats calculation infrastructure from Google BigQuery to Apache Spark I also removed the BigQuery references from the ListenBrainz website. Now that the timescale migration work became stable, I began working on Delete a Listen feature.
Pulling out the front end brushes
Now that the base was ready for us to work on, I started working on the React components so that the feedback and deletion feature could actually be presented on the website. Around the same time, the Timescale release day was also getting near, so I helped with a few tests and finished up the work for deleting listens. The front end components also started looking good and we were ready to associate the back end with them.
Rectifying & Reactifying
It’s high time and the final phase started. Now that we were ready with a few components we needed some tweaks in some production components to make them subtle. Hence I shot an improvement PR to tweak some shadows, adjust some fonts, adjust heights of the components, sticking the footer to the bottom, and reactify the loading spinner. Then came the Listen Count Card denoting the number of listens for a user. Following this we moved to Card based design for displaying listens.
This was followed by the much awaited feedback controls and now we can love/hate the songs from our listen collection. Isn’t this amazing! There were some needed minor tweaks needed to handle the ‘playing now’ listens correctly. At the same time, following the MetaBrainz guidelines to write quality code, I worked on making the SQL queries more readable. Then came the much awaited Delete a Listen feature and now we can finally get rid of the embarrassing listens!!
Oh, now comes the time when we talk about the current scenario. The tasks currently on my radar are adding cover art support so that the page looks more alive and improving the Spotify imports to only import listens that were listened by the user after the latest Spotify listen we have for them.
After this I aim to work on the recommendation stuff that’s being actively pursued by the team. Also Mr_Monkey and me had been working on some design concepts for the All New ListenBrainz. I am pretty excited to work on it. Wanna take a sneak peek?
A new fam
The journey with MetaBrainz has been so amazing, that I am so tempted to stick here. I feel ecstatic to be a part of GSoC with the best org 🙂 . The best part is – it’s never all about code. There’s a lot to gain. Each day marked gaining maturity and thinking more and more like a real developer. I started feeling at ease with the communicate → code → integrate chain. It really feels fortunate to be a part of the MetaBrainz family where everyone is a ping away <3 .
GSoC marks the kickstart of my journey with MetaBrainz and I will be here lurking on IRC, shooting PRs to make the projects more and more awesome.
Heartiest Gratitude
Robert Kaye (ruaok) for being a mentor and a companion, guiding me through the dev life and real life.
Param Singh (iliekcomputers) for always keeping the spirits high.
Nicolas Pelletier (Mr_Monkey) for guarding me against Cascading Snot Swab issues.
Alastair Porter (alastairp) for fishing out the best practices from his pool of intelligence.
Vansika Pareek (pristine___) for some awesome playlists.