Hi, I’m Leo and I spent my summer building and training SpamBrainz, our new solution to fighting spam in MusicBrainz. If you haven’t heard of SpamBrainz before it’s probably because it did not exist before this year’s Summer of Code.
For quite a while now the amount of spam in MusicBrainz has started to become a serious problem. Often this means editors are automatically created with descriptions that look not unlike the spam emails most of us get every day, promoting other websites and services.
During last year’s MetaBrainz Summit we discussed possible solutions to this and came up with the Spam Ninja system. Essentially this means that Soon™ there will be a group of editors that receive spam reports and have the ability to delete editors and entities that are nothing but spam.
Now with MusicBrainz having almost two million registered editors, could we really expect the Spam Ninjas to manually check every single one of them in addition to all the new registrations? Obviously not, and this is where SpamBrainz comes in.
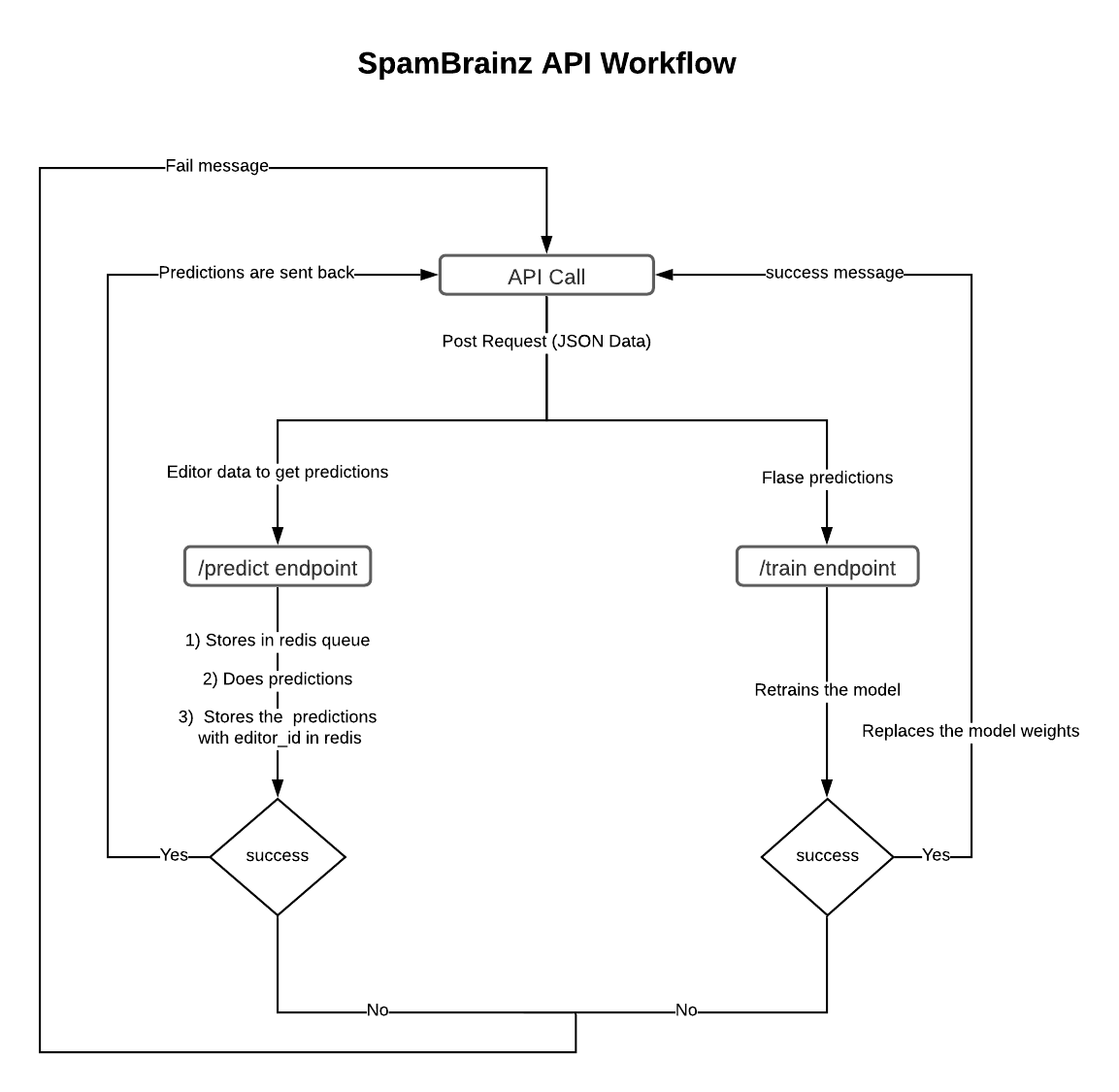
SpamBrainz is a machine learning system that looks at all editors and decides whether or not it thinks they are spammers. If it thinks they are, it automatically notifies the spam ninjas who then decide whether or not SpamBrainz was correct.
What’s great about this system is that a human is guaranteed to look at any report and at no point does a computer decide that you’re a spammer and should be banned, because no one wants machines to run the world, right?
Building SpamBrainz
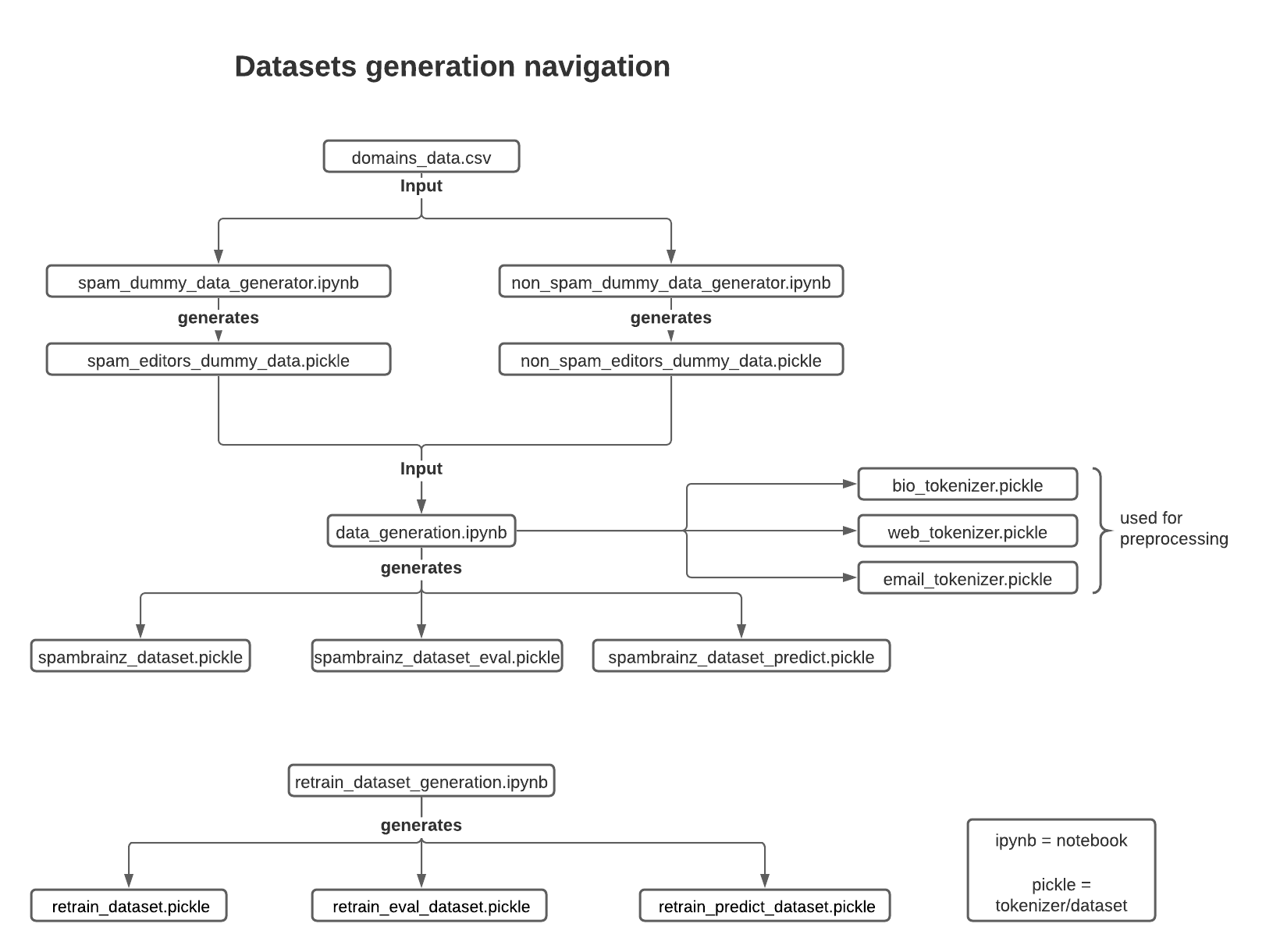
While most GSoC projects involve adding features to existing systems, SpamBrainz is something entirely new and I had not built anything on this scale before so I started out by doing tons of research.
When building a machine learning project you should always start by doing some good
old statistics first and trying to figure out what matters about your data and how the
system could use it. I wrote a couple Jupyter notebooks (which are great for working with data) to do this.
As I was not working for MetaBrainz at the time and had to respect our privacy policy, I wrote a script to collect the most common values of a couple different editors, anonymize them and save them to a report. Using that data I could compare all spam and non-spam editors and decide upon a set of datapoints that would be useful for my machine learning model. Yvanzo then ran these on the live database and I could happily do my data analysis without compromising user privacy.
Next I built a pretty boring Flask-based API that would allow MusicBrainz to queue up editor analysis and training. Quite a few different MetaBrainz projects use Python and need to access the MusicBrainz database so a long time ago someone wise decided to move commonly used code into a repository called brainzutils-python. All I had to do was to add some code for accessing editor data through it.
In a surprise move by ruaok I was then hired by MetaBrainz as a contractor with a yearly salary of 100g of chocolate. I probably should have negotiated what kind of chocolate but what mattered most was that I could now work with user data without breaching our privacy policy.
But before I could build my Keras model I had to decide on a final set of input features and do write code for preprocessing the data. Only then could I finally get started building and testing models.
The current SpamBrainz state of the art model is Lodbrok which actually turned out to work really well, reaching a 99% accuracy in detecting spam while only mis‐classifying 0.2% of real users as spammers. Obviously the latter won’t be a problem because after all a Spam Ninja will still check these reports.
Future outlook
Now that GSoC is over I could just disappear with all the money and leave SpamBrainz in its current state but obviously that’s not what I am planning to do.
I would like to work with zas on getting it deployed along with the Spam Ninja system, improve the code documentation and try to tackle the remaining problem that is online learning (which as it turns out, isn’t as easy as I had thought).
With spam always evolving and spammers already moving to more sophisticated methods than just using editor biographies, I’d also look into building separate models for other entities.
After all SpamBrainz is just getting started and I’m very much looking forward to continuing our journey towards reducing the spam we all have to endure on MusicBrainz and other MetaBrainz projects.